« Text mining de forums » : différence entre les versions
mAucun résumé des modifications |
|||
| Ligne 97 : | Ligne 97 : | ||
==Extraction de données dans un Forum== | ==Extraction de données dans un Forum== | ||
Partie rédigée par [[Utilisateur:Mattia A. Fritz|Mattia A. Fritz]] | |||
* Voir la page [[web scraping]] pour un aperçu général de l'extraction des données depuis des pages web | * Voir la page [[web scraping]] pour un aperçu général de l'extraction des données depuis des pages web | ||
Version du 4 janvier 2015 à 14:49
| Analytique et exploration de données | |
|---|---|
| Module: Text mining | |
| ⚐ à finaliser | ☸ intermédiaire |
| ⚒ 2015/01/04 | |
| Catégorie: Analytique et exploration de données | |
Introduction
Dans les dispositifs de formation hybrides ou les dispositifs de formation entièrement à distance, les forums sont régulièrement utilisés pour établir et stimuler l’interaction de l’enseignant avec les étudiants, mais également l'interaction entre pairs (entre étudiants).
Les forums peuvent être utiles à l'enseignant pour évaluer les étudiants, mais aussi pour évaluer son enseignement. En effet, les discussions asynchrones peuvent être sources d'apprentissage puisque la participation des étudiants au forum leur permet de réfléchir sur les contenus du cours, ainsi que d'échanger et de confronter leurs points de vue avec ceux des autres étudiants, dans une perspective socio-constructivste. Les messages postés par les étudiants dans les forums de cours sont des données très utiles, dans le sens où elles permettent à l'enseignant d'observer des informations sur les étudiants, que ce soit sur un étudiant particulier ou sur sa classe en général. Effectivement, l'enseignant peut par exemple voir quels sont les contenus, thématiques, parties du cours qui posent problème aux étudiants, il peut alors adapter son enseignement en fonction de ces informations.
Toutefois, si l’enseignant a un grand nombre d’étudiant cette analyse « manuelle » peut prendre énormément de temps : l'enseignant doit passer en revue l'ensemble des fils de discussions et l'ensemble des messages pour obtenir des données.
Le text mining permet d'automatiser le traitement de volumes conséquents de contenus textuels pour en extraire les principales caractéristiques et tendances, afin de relever de manière statistique les sujets, les connaissances, les thèmes qui y sont évoqués. Cette technique permet alors à l'enseignant d'automatiser le traitement des données contenues dans le forum de son cours et d'obtenir rapidement des éléments permettant l'évaluation des étudiants et/ou de son enseignement.
Afin de montrer en quoi et comment le text mining permet ceci, nous avons pris l'exemple d'une formation à distance aux compétences numériques proposée aux étudiants de première année de Bachelor dans le cadre de la Faculté de Psychologie et des Sciences de l'Education. Nous nous intéresserons au premier module, le module traitement de texte qui comporte six chapitres. Les étudiants sont suivis et accompagnés par des tuteurs via un cours sur la plateforme Moodle de l'UNIGE. Il est demandé aux étudiants qu'ils participent activement et régulièrement au forum de leur groupe. L'idée étant que chaque étudiant poste un message minimum par semaine, que ce soit une réaction, une question ou une réponse en lien avec le chapitre en cours. Cette participation est l'une des conditions pour obtenir l'attestation de suivi de formation au terme de celle-ci.
A ce stade, il nous paraît intéressant de réaliser une revue de la littérature concernant le text mining appliqué à des forums, plus précisément à des forums utilisés dans un cadre pédagogique, afin de voir ce qui a été déjà fait à ce sujet.
Revue de la littérature
Dans les cours à distance, les enseignants souhaitent souvent pouvoir évaluer le niveau et la qualité des activités des étudiants dans les forums. Cependant, de nombreux problèmes contribuent à la difficulté d'évaluer l'activité dans un forum et à fournir aux élèves une rétroaction significative sur leur progrès. L'enseignant doit tout d’abord savoir quelles informations sont utiles et pertinentes (Dringus & Ellis, 2005).
En 2005, Dringus & Ellis se sont intéressés à la manière dont le text mining peut être utilisé pour réduire les difficultés auxquelles les enseignants sont confrontés dans l’évaluation des activités des étudiants dans les forums de cours. Dans leur article, les auteurs poursuivent trois buts :
- Discuter des problèmes liés au système général qui contribue à la difficulté d'évaluer les forums de discussion asynchrone.
- Identifier les indicateurs de participation communs sur lesquels les enseignants peuvent se baser pour évaluer le progrès de l'élève et les discussions en ligne.
- Décrire et l'exploration de données et le text mining comme une stratégie pour évaluer les activités des étudiants dans les forums.
Dringus & Ellis (2005) suggèrent plusieurs indicateurs de participation pouvant être extraits des discussions et pouvant servir à l’évaluation par l’enseignant, comme par exemple, l’utilisation du text mining pour déterminer la distribution et la fréquence des contributions par les étudiants tout au long du forum ou encore pour identifier les initiatives ou les questions, ainsi que le temps de réponse au premier post.
Voici l’ensemble des indicateurs proposés :

Selon ces auteurs la technique du text mining est une solution possible pour aider l’enseignant à analyser les discussions des forums et à obtenir des informations permettant ensuite d’évaluer l’étudiant.
Cette vision est partagée par Azevedo, Reategui et Behar (2011) qui ont mené une étude sur l’utilisation de la technique du text mining pour analyser la pertinence des messages dans un forum en ligne.
Selon ces auteurs, les discussions asynchrones, via un forum, permettent d’établir et de stimuler l’interaction de l’enseignant avec les étudiants, mais également des étudiants entre eux. De plus, ces discussions sont sources d’apprentissage, puisque la participation des étudiants au forum leur permet de réfléchir sur les contenus du cours. L’implication des étudiants sur les forums est donc une activité importante dans les cours en ligne, puisqu’elle permet à l’enseignant d’observer des informations sur les étudiants. Toutefois, si l’enseignant a un grand nombre d’étudiant, cette analyse « manuelle » peut prendre énormément de temps.
Les auteurs proposent un outil de text mining, MineraFórum, qui relève les différentes thématiques abordées dans les discussions et qui permet de les présenter sous forme de graphique. Cet outil permet également d’obtenir un rapport contenant des informations sur le nombre total de posts par chaque utilisateur, la quantité de contributions pertinentes et non pertinentes par chacun et les concepts importants utilisés dans les contributions, considérés comme pertinents dans la discussion.
López, Luna, Romero et Ventura (2012) ont réalisé une étude dont l’objectif était de montrer s’il existe ou non une corrélation entre la participation des étudiants sur Moodle et leur note finale au cours.
Pour mesurer la participation au forum, les auteurs se sont basés sur plusieurs indicateurs :
- Le nombre de messages créés par l’étudiant
- Le nombre de fil de discussion créés par l’étudiant
- Le nombre de réponses envoyées par l’étudiant
- Le nombre de mots écrits par l’étudiant
- Le nombre de phrase écrits par l’étudiant
- Le nombre de messages lus
- Le total de temps passé sur le forum
Ces indicateurs nous semblent intéressants pour pouvoir évaluer la participation d’un étudiant sur un forum de cours.
Toujours en lien avec le text mining, mais selon une autre approche, Kim, Shaw, Chern et Feng (2007) proposent un outil de réponse automatique aux questions posées dans les forums. Leur étude a montré que chaque post d’une discussion peut être catégorisé selon le type d’actes du langage qu’il implique : question, réponse, élaboration, soutien et correction, afin de déterminer le rôle joué par l’enseignant et les étudiants dans les discussions.
Voici les différents types d’actes de langage qu’ils ont relevés :
| Speech act | Exemples |
|---|---|
| ACK/SUPP = Soutien | "good job", "correct", "you got it" … |
| ANS/ SUG = Réponse/suggestion | "perhaps" "how about" "you might","you probably"
"maybe", "try", "i think", "I am/was thinking" "I'm guessing", "my guess" "it should" "it seems" "look at", "check" |
| ANNO = Annonce | "office hours" |
| CORR/OBJ = Correction/objection | "doesn't mean" "are you sure" "what/ how
about“"didn't work" / "not successful/ "better/ faster/ quicker way"- "i don't think it will work" / "not work" + ... "problem" |
| QUES = Question | "how" "what" "can we" "are"/ "is" "why"
"just/were/was wondering" "I/we have a question" "my question" |
| ELAB = Elaboration | Pas d’exemples donnés par les auteurs |
Leur outil intelligent utilise des techniques de fouille de texte, afin d’extraire les mots et leur fréquence dans les questions des élèves, dans les documents de cours, et dans les discussions précédentes.
Lin, Hsieh et Chuang (2009) ont également utilisé la technique du text mining pour identifier les différents genres textuels dans les discussions en ligne. Ils ont proposé un système pour classifier les genres de contributions textuelles. Ils en ont identifiés six types : annonces, questions, explications, interprétations, conflits, affirmation.
Extraction de données dans un Forum
Partie rédigée par Mattia A. Fritz
- Voir la page web scraping pour un aperçu général de l'extraction des données depuis des pages web
Les forums représentent des éléments très intéressants dans la perspective du text mining car ils proposent du contenu structuré selon des critères sémantiques (i.e. thématique, argument du fil de discussion, etc.) normalement produit par différents auteurs. Contrairement à une page de blog (sans commentaires) ou à un page web "informative" dont le contenu reflète la volonté communicationnelle d'une seule personne (ou une volonté conjointe entre plusieurs personnes), un forum propose plusieurs points de vue différents qui s'articulent dans une dynamique dialogique. En d'autres termes, dans une perspective analytique, les forums sont à la fois un lieu d'analyse des donnés en tant qu'information, mais également des donnés en tant qu'interaction - et donc comportement.
Au niveau de l'extraction des données, les caractéristiques propres au forums posent certaines difficultés qui nécessitent souvent une extraction plus complexe par rapport aux "simple" web scraping. De suite une liste non exhaustive de ces difficultés.
Différents niveaux de granularité de l'analyse
La plupart des forums est construite selon une architecture hiérarchique du type : Forum > Catégories > Sections > Discussions. À chaque niveau, tout élément est supposé entretenir avec les autres élément du même niveau un rapport de type sémantique afin qu'un équilibre entre similarité et particularité soit atteint. Par exemple, les sections d'une catégorie doivent se rapprocher afin que leur appartenance à cette catégorie soit justifiée, mais en même temps elles doivent justifier leur existence par rapports aux autres sections (i.e. apporter quelque chose d'unique). Une analyse peut par conséquent être menée à différents niveau de granularité :
- l'entier du Forum ;
- une ou plusieurs catégories du Forum ;
- une ou plusieurs sections d'une ou plusieurs catégories ;
- ... et ainsi de suite.
La granularité la plus fine que l'on peut atteindre est normalement un message individuel d'un fil de discussion qui - dans une comparaison linguistique - représente de quelque sorte la plus petite unité de sens d'un Forum.
Le choix du niveau d'analyse comporte plusieurs enjeux qui dépendent également des caractéristiques techniques du Forum (ouvert au public, modéré, etc.). Généralement, un analyse au niveau du Forum entier permet le traitement d'une grande quantité de données, mais augmente la probabilité que des éléments hors sujet soient présents dans le corpus. À l'autre extrême, une analyse dans un fil de discussion individuel comporte moins de données, mais une majeure probabilité d'analyser des données qui présentent une certaine homogénéité par rapport à l'argument d'intérêt.
Au niveau technique, la difficulté de l'extraction est proportionnelle à la quantité des niveaux et sous-niveaux analysées. Une analyse sur l'entier du Forum nécessite très probablement d'une extraction de type automatique, voire un accès direct à la base des données, c'est-à-dire sans passer à travers l'interface web (i.e. les pages). Au contraire, une analyse sur un fil de discussion peut se faire de manière manuelle ou semi-automatique, même si certains fils de discussion peuvent s'étaler sur plusieurs pages. Certains types de Forum permettent à ce sujet d'exporter la discussion afin que tous les messages apparaissent sur une seule page.
Analyse du contenu vs. analyse de l'interaction
Une page qui propose le contenu d'un fil de discussion d'un forum peut être perçue de deux manières différentes impliquant deux structures sous-jacentes différentes :
- Un corpus résultant du fusionnement de l'ensemble des productions de chaque auteur. Dans cette perspective le corpus assume une sorte de "volonté propre" qui est la somme indistincte des actes communicationnels des participants.
- La structure sous-jacente des données est plutôt similaire à celle d'un texte brut, non structuré.
- Un corpus résultant des dynamiques dialogiques des différents auteurs. Dans cette perspective le corpus assume un caractère interactif qui dérive du changement de rôle des acteurs qui sont parfois des émetteurs et parfois des récepteurs au niveau communicationnel.
- La structure sous-jacente des données est plutôt similaire à un document XML, bien structuré, dans lequel on peut retracer le contenu, son auteur, et même son positionnement dans le fil de discussion (chronologique ou hiérarchique)
Au niveau technique, la difficulté de l'extraction est majeure dans la perspective interactive, car les données ne doivent pas seulement être extraites, mais également permettre des références croisées. À ce propos, le nom de l'auteur et le texte du message sont souvent dans deux noeuds différents au niveau de la structure du DOM. En effet, très souvent la structure d'un message d'un forum se compose de deux colonnes d'un tableau : dans la première il y a le nom de l'auteur du message (ainsi que d'autres informations para-textuelles), et dans la deuxième le texte du message (ainsi que d'autres informations para-textuelles encore). Pour extraire et mettre en relation auteur et texte il faut donc entamer un processus itératif de ce type :
- Identifier dans la structure de la page l'élément "conteneur" du message, il s'agit souvent d'un tableau ou d'un ligne de tableau (i.e. balise
tr) - Identifier dans l'élément conteneur l'élément qui contient le nom de l'auteur. Il s'agit très souvent du nom de l'utilisateur et par conséquent il est utilisé également comme lien hypertextuel au profil de l'utilisateur (i.e. balise
a) - Identifier dans l'élément conteneur l'élément qui contient le texte du message. Il s'agit dans ce cas souvent d'un élément de type
divqui a parfois une classe qui permet de l'identifier facilement dans la structure (e.g. "post", "fulltext", ...)
Idéalement, à chaque itération de ce processus un nouveau nœud XML devrait être créé pour obtenir un document final similaire à celui-ci :
<corpus>
<message>
<auteur>Utilisateur X</auteur>
<texte>Texte du message 1</texte>
</message>
<message>
<auteur>Utilisateur Y</auteur>
<texte>Texte du message 2</texte>
</message>
</corpus>
L'identification de l'auteur dans un nœud XML séparé du contenu facilite l'évitement des conflits avec des noms d'utilisateurs utilisés dans le texte (e.g. la notation @Utilisateur utilisé souvent pour adresser une réponse directe). Ce schéma peut bien sûr être étendu avec d'autres informations telles que la date du message, le titre, etc.
Fonctionnalités techniques qui rendent l'analyse plus difficile
Le rôle des forums est de faciliter l'échange entre les utilisateurs et par conséquent les plateformes proposent souvent des fonctionnalités techniques qui permettent de se repérer dans le flux de discussion ou de "protéger" le bon déroulement de la discussion. Parmi ces éléments on trouve :
- Les citations d'autres messages: un utilisateur peut citer - i.e. "englober" dans son message - une partie ou la totalité d'un message d'un autre utilisateur. La partie cité apparait souvent avec un style différent, par exemple en italique ou avec une couleur de fond différente.
- Les réponses à d'autres messages : un utilisateur peut viser son intervention expressément en fonction d'un autre message. Les plateforme gèrent cette fonctionnalité ainsi que les réponses sont juxtaposées après le message avec souvent une indentation. L'affichage des messages ne suit donc plus l'ordre chronologique des posts.
- La modération : des utilisateurs du forum disposent de pouvoirs techniques qui leur permettent d'effacer ou modifier le contenu d'un message qui ne respecte pas les règles de la plateforme
Ces fonctionnalités peuvent cependant obstruer une extraction de données. Voici pour chaque fonctionnalité une description des problèmes potentiels.
Les citations
Les citations représentent des éléments récursifs qui n'apporte rien de nouveau d'un point de vue informationnel, car il s'agit exactement du même contenu proposé simplement dans des endroits différents du flux de discussion. Cette récursivité risque de biaiser certains type d'analyses. Dans une analyse de fréquence, par exemple, les mots contenus dans une citation seraient comptés deux fois sans que ces mots aient été effectivement produits. Même dans le cadre d'une analyse assez simple qui vise mesurer la taille des messages des utilisateurs, un message qui en cite un autre aura de toute manière une longueur supérieur à l'original même si l'auteur se limite à quelques lignes de commentaires. Dans un classement des contributeurs, l'auteur du message avec citation aurait par conséquent un meilleure position de l'auteur du contenu original, même si ce dernier a en réalité écrit beaucoup plus.
Selon le type d'analyse prévue, il serait donc parfois nécessaire d'effacer les citations du corpus afin que l'analyse prenne en compte seulement du contenu "original", c'est-à-dire qui n'apparait pas à d'autres endroits du fil de discussion. On peut utiliser des expressions régulières ou exploiter les caractéristiques de style des textes cités pour les exclure du corpus, mais néanmoins il reste certains cadres de figure qui rendent cette opération difficile, voire impossible :
- Le code utilisé pour la citation d'un autre message peut être utilisé pour citer du contenu qui provient d'autres sources (e.g. articles, pages wiki, etc.). L'exclusion de tous les éléments de style qui contiennent une citation risque ainsi d'effacer aussi du contenu "original" du point de vue du fil de discussion.
- Les utilisateurs fragmentent parfois les citations en différentes morceaux afin qu'ils puissent répondre ponctuellement à des passages du message original. Cette pratique rend inefficace une exclusion de type auto-recursive (on cherche le texte d'un message à l'intérieur d'autres messages et on efface toute correspondance) car le texte du message originale n'apparaît plus exactement avec la même structure, mais il est interpolé avec du nouveau texte.
- Les utilisateurs peuvent citer "manuellement" des passages du texte d'autrui avec du copier/coller et des guillemets
D'autre côté, les citations sont un élément très utile dans la perspective d'une analyse de la dynamique dialogique car elles permettent assez facilement d'établir des liens directs entre les messages d'un fil de discussion.
Les réponses
Les réponses aux messages structurent le fil de discussion de manière logique plutôt que chronologique. De cette manière, en effet, les messages forment une arborescence déterminée par le lien directe entre un message et sa (ou ses) réponse(s). Une indentation (i.e. un marge incrémental sur le côté gauche) signale souvent cette arborescence de manière graphique. Cette fonctionnalité peut poser quelques difficultés lors d'une extraction notamment en ce qui concerne :
- Les extractions automatiques qui s'étalent dans le temps : ce type d'extraction contrôle souvent de manière incrémentale si des éléments ont été ajoutés à la fin du fil de discussion. Dans le cas d'une hiérarchisation non-chronologique, tout le fil de discussion devra être analysé à zéro.
- Les extractions qui se basent sur la structure du DOM : les réponses sont souvent imbriquées dans l'élément qui représente le message auquel elles font suite. Dans une extraction basée sur la hiérarchie des éléments (e.g. XPath), il est difficile de prévoir tout les niveaux d'indentation qui peuvent se créer.
Tout comme les citations, néanmoins, les forums structurés en fonction des réponses permettent une analyse plus facile de la dynamique dialogique.
La modération
La modération (y compris l'auto-modération, c'est-à-dire la possibilité d'effacer ou modifier ses propres messages) permet aux acteurs en jeu de protéger la discussion en manipulant du contenu qui n'est pas jugé adéquat - pour des raisons de compréhensibilité ou d'uniformité aux règles d'édition. Cette fonctionnalité techniques présentent quelques difficultés dans la perspective d'une extraction de données :
- Dans une analyse qui s'étale dans le temps, la manipulation à posteriori de messages altère les données qui ont déjà été recueillies auparavant. Notamment dans le cas de fils de discussion divisés sur plusieurs pages, l'effacement de messages recalibre la dispersion des messages sur les pages. Ceci rend plus compliqué la synchronisation des données sans avoir à refaire à chaque fois une nouvelle analyse qui peut être coûteuse en terme de temps et de ressources de computation.
- Les messages censurés ont parfois été cités avant qu'ils soient effacés, pourtant il se crée une incongruence car le texte du message original figure encore en citation dans d'autres messages. Ceci rend encore plus compliqué la probabilité de pouvoir écarter les citations (voir plus haut dans cette section)
Les questions auxquelles nous souhaitons répondre
1. Termes qui apparaissent le plus souvent
- Pour chaque chapitre, quels sont les termes qui reviennent le plus souvent ?
- Pour l'ensemble du module traitement de texte, quels sont les termes qui reviennent le plus souvent ?
2. Nombre de messages postés par étudiant
- Pour chaque chapitre, combien chaque étudiant a-t-il posté de messages ?
- Pour l'ensemble du module traitement de texte, combien chaque étudiant a-t-il posté de messages ?
3. Nombre de questions posées
- Pour chaque chapitre, combien y a-t-il de questions posées ?
- Pour l'ensemble du module traitement de texte, combien y a-t-il de questions posées ?
Text mining appliqué au forum d'une formation à distance : solutions exemplaires
Constitution du corpus
Une analyse sur un forum peut être réalisée à différents niveaux de granularité (entier du forum, une ou plusieurs catégories du forum, un ou plusieurs fils de discussion, un ou plusieurs messages d'un fil de discussion).
Dans notre exemple, nous avons décidé de mener notre analyse sur plusieurs fils de discussions.
Le corpus est ainsi constitué de six fils de discussion issus du forum d'un des groupes du cours à distance aux compétences numériques. Chacun de ces fils de discussion correspond à un chapitre du module traitement de texte :
- Chapitre 1 : Dossiers, fichiers et documents
- Chapitre 2 : L'environnement des logiciels de traitement de texte
- Chapitre 3 : Mise en forme de texte
- Chapitre 4 : Mise en forme des caractères et des paragraphes
- Chapitre 5 : Les styles
- Chapitre 6 : Éléments de mise en page du document
Chaque fil de discussion contient en moyenne une vingtaine de messages.
Dans un premier temps, nous avons enregistré chaque fil de discussion du forum. Pour ce faire, il suffit d'aller dans le fil de discussion et de faire un clic droit, puis d'enregistrer sous.

Le résultat est un fichier HTML contenant l'ensemble des informations présentes sur la page. Le problème réside alors dans le fait que le fichier contient de nombreuses informations inutiles dans le cadre de nos analyses. Il nous a fallu alors "nettoyer" le corpus.
Filtrage/nettoyage
Dans le cadre de nos analyses, nous avions besoin de deux types d'information : le nom de l'auteur du message (anonymisé, pour des raisons de confidentialité) et le texte du message.
Pour ce faire, nous avons réalisé ce qui est présenté au point 2.2.
Au terme du nettoyage, nous avons obtenu deux types de fichiers :
- Un fichier .docx (que nous avons également enregistré en version .txt)
- Un fichier .xml
Ces deux fichiers contiennent l'ensemble des messages des six fils de discussions accompagnés de son auteur, représenté par un code sous la forme UserXXXXX (le code étant toujours le même pour chaque auteur dans l'ensemble du corpus). Étant donné que nous souhaitons réaliser des analyses de deux types :
- Sur chaque fil de discussion séparé
- Sur l'ensemble du corpus
Il nous faut transformer quelques peu nos fichiers de manière à obtenir un fichier par fil de discussion.
Transformation des fichiers
Pour obtenir un fichier par fil de discussion, il suffit de supprimer les données inutiles, c'est-à-dire de garder uniquement celles concernant le fil de discussion qui nous intéresse, puis d'enregistrer le fichier sous un nouveau nom.
Analyses et interprétation des résultats
Question 1 : Termes qui apparaissent le plus souvent
Avec IRaMuTeQ (à venir)
Question 2 : Nombre de messages postés par étudiant
Avec Voyant Tool (à venir) Aussi avec R (à venir)
Question 3 : Nombre de questions posées
- Pour chaque chapitre, combien y a-t-il de questions posées ?
- Pour l'ensemble du module traitement de texte, combien y a-t-il de questions posées ?
Pour répondre à ces questions, nous avons utilisé R.
Dans un premier temps, il est nécessaire d'indiquer à R où trouver les fichiers sur lesquels nous travaillons. Pour ce faire, il suffit d'aller dans "Fichier" --> "Changer le répertoire courant" --> chercher le dossier contenant les fichiers du corpus.
Nous allons commencer par répondre à la question suivante : Pour le chapitre 1, combien y a-t-il de questions posées ?
Pour ce faire, il nous faut tout d'abord segmenter notre corpus en unités, c'est-à-dire créer un tableau à partir du corpus.
Il est possible de segmenter le fichier en lignes. Nous utilisons la fonction readLines qui lit notre fichier chap1.txt ligne par ligne :
corpus <-readLines("chap1.txt")

Chaque ligne est associée à un nombre entre crochets.
Il est également possible de segmenter le fichier en "character", c'est-à-dire en mots, espaces, etc. Nous utilisons la fonction scan :
corpus <- scan ("chap1.txt", what="character", sep="")
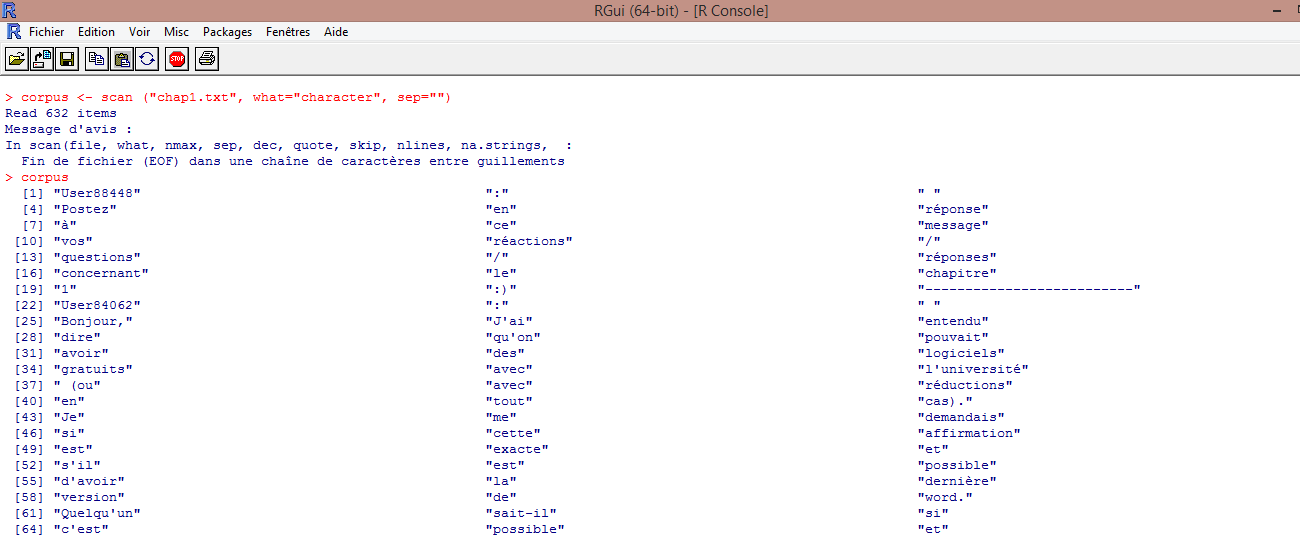

Chaque caractère est associé à un nombre entre crochets.
Nous avons opté pour cette option.
Dans un deuxième temps, nous allons rechercher, à travers des expressions régulières, des co-occurences. Ici, nous recherchons l'occurrence "?", puisque nous partons du principe qu'une question se reconnaît à son point d'interrogation.
La commande suivante grep("\\?", corpus) permet de repérer où apparaissent les points d'interrogation en donnant les nombre entre crochets correspondant :

Il est possible de compter chaque résultat, mais si nous en avons un grand nombre cela prendrait trop de temps. Il est alors possible d'utiliser les commandes suivantes :
num <- grep("\\?", corpus)
> num
> length(num)
Dans R cela donne :
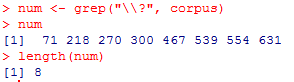

La première ligne nous redonne les endroits du corpus qui présentent un point d'interrogation. La commande length(num) permet de compter le nombre de point d'interrogation.
Dans le chapitre1, il y a ainsi 8 points d'interrogation présents, c'est-à-dire 8 questions posées.
Voici une commande regroupant l'ensemble des étapes réalisées pour obtenir le nombre de point d'interrogation :
length(grep("\\?", scan("chap1.txt", what="character")))
En utilisant cette commande, on obtient directement le résultat attendu :


Nous avons utilisé cette même commande pour l'ensemble des chapitres, c'est-à-dire en remplaçant "chap1.txt" par le nom des autres fichiers. Nous obtenons les résultats suivants :
(à venir)
Conclusion
Références bibliographiques
- Azevedo, B. F. T., Reategui, E. B. & Behar, P. A. (2011). Automatic analysis of messages in discussion forum. 14th International Conference on Interactive Collaborative Learning (ICL2011) ̶ 11th International Conference Virtual University (vu'11) : Piešťany, Slovakia.
- Dringus, L. P. & Ellis, T. (2005). Using data mining as a strategy for assessing asynchronous discussion forums, Computers & Education, 45, 41–160.
- Kim, J., Shaw, E., Chern, G. & Feng, D. (2007). An Intelligent Discussion-Bot for Guiding Student Interactions in Threaded Discussions. AAAI Spring Symposium on Interaction Challenges for Intelligent Assistants. Stanford University.
- Lin, F, Hsieh, L. & Chuang, F. (2009). Discovering genres of online discussion threads via text mining, Computers & Education, 52(2), 481-495.
- López, M.I., Luna, J. M., Romero, C. & Ventura, S. (2012). Classification via clustering for predicting final marks based on student participation in forums. In Proceedings of the 5th International Conference on Educational Data Mining (pp.148-151).