« Introduction conceptuelle à R » : différence entre les versions
| Ligne 352 : | Ligne 352 : | ||
La phase de computation est également celle dans laquelle les problèmes apparaissent, car l'interprète n'arrive pas à exécuter les instructions données à cause d'erreurs (ou ''bugs'') dans le code. Malheureusement, les messages d'erreurs fournis par [[R]] ne sont souvent pas très clairs, ce qui n'aide pas surtout les néophytes à comprendre les raisons des interruptions de la computation. | La phase de computation est également celle dans laquelle les problèmes apparaissent, car l'interprète n'arrive pas à exécuter les instructions données à cause d'erreurs (ou ''bugs'') dans le code. Malheureusement, les messages d'erreurs fournis par [[R]] ne sont souvent pas très clairs, ce qui n'aide pas surtout les néophytes à comprendre les raisons des interruptions de la computation. | ||
Par exemple, l'image plus bas montre deux types d'erreurs assez fréquents dans l'utilisation de[[R]] : | Par exemple, l'image plus bas montre deux types d'erreurs assez fréquents dans l'utilisation de [[R]] : | ||
[[Fichier:RStudio error in console.png|600px|vignette|néant|Deux types d'erreurs fréquents : erreur de syntaxe et instruction incomplète ]] | [[Fichier:RStudio error in console.png|600px|vignette|néant|Deux types d'erreurs fréquents : erreur de syntaxe et instruction incomplète ]] | ||
Version du 9 octobre 2019 à 09:29
Cet article est en construction: un auteur est en train de le modifier.
En principe, le ou les auteurs en question devraient bientôt présenter une meilleure version.
Introduction
On se réfère à R souvent comme s'il s'agissait d'une entité unique, notamment un logiciel à utiliser pour des analyses statistiques, mais la réalité est un peu plus complexe. Cette introduction conceptuelle à R vise identifier différentes composantes de R et la manière dont elles s'articulent entre elles pour fournir un écosystème puissant et flexible. Contrairement à d'autres introductions à R qui sont basées principalement sur la découverte des particularités du langage, nous proposons ici plutôt un survol conceptuel qui puisse s'intégrer avec des approches plus pragmatiques.
Prérequis
Dans cette introduction conceptuelle, nous utiliserons l'environnement de travail typique de R, notamment avec l'utilisation de RStudio qui nous permettra de mieux cerner certains aspects comme par exemple la notion de référence symbolique, fonction, paquet, session, environnement et d'autres encore. Pour maximiser la compréhension de ces aspects, sur le plan théorique, il peut être utile d'avoir lu au préalable l'Introduction à la programmation.
Fonctionnement général de R
L'utilisation de R se fait à travers des instructions qui sont passées à un interprète en tant que Input. Ces instructions déclenchent de la computation, c'est-à-dire qu'elles sont interprétées, afin de produire un Output correspondant. Cet Ouput peut ensuite servir, éventuellement, en tant que Input pour une nouvelle computation, en créant ainsi un mécanisme cyclique représenté dans la figure suivante.

Ces trois phases sont généralement effectuées au sein de la même interface graphique, par exemple à travers RStudio ou la ligne de commande qui est disponible dans la version R de base. Néanmoins, le fait que ces trois phases puissent être décomposées permet une plus grande flexibilité et des opportunités intéressantes pour chaque phase :
- Input
- Les instructions peuvent être produites de différentes manières, par exemple à travers du code ou même à travers une interface graphique créé ponctuellement pour mener à bien un type d'analyse bien spécifique (voir par exemple les ShinyApps). La production des instructions peut être faite à travers un éditeur de texte avec aide à la syntaxe, étalée sur plusieurs fichiers pour gérer la complexité d'une analyse articulée, ou encore organisée en procédures réutilisables à différents endroits et pour des projets différents.
- Computation
- La computation, c'est-à-dire l'interprétation des instructions de Input, peut se faire sur la même machine où les instructions ont été écrites ou sur une ou plusieurs machines différentes. Ceci permet par exemple de lancer des analyses qui nécessitent d'une grande puissance computationnelle sur des serveurs distants, qui tournent pendant plusieurs heures, voire jours, avant d'atteindre le(s) résultat(s) correspondant(s).
- Output
- Le résultat des instructions peut être récupéré et affiché de différentes manières, de la plus simple (e.g. résultat textuel dans la ligne de commande) à la plus complexe (e.g. la génération d'un report scientifique intégrant du texte, des figures, références, tableaux, etc.).
L'enjeu principal dans l'utilisation de R réside donc dans la création des instructions instrumentales aux résultats souhaités, un mécanisme qui peut s'avérer complexe car il présuppose la synergie des plusieurs composantes, ainsi que le respect de contraintes spécifiques au niveau de ce qui est considérée une série d'instructions interprétables par R. Nous proposons de suite une description plus approfondie des trois composantes Input-Computation-Output. Ceci nous permettra de préparer le terrain pour des concepts plus spécifiques et récurrents dans l'utilisation de R.
Input : la génération d'instructions valables
Dans la plupart des cas, la génération de l'Input en R se fait à travers l'écriture de code. Les instructions dans le contexte de la programmation sont appelées algorithmes et nous utiliserons les deux termes de manière interchangeable par la suite.
# Instruction 1
# Instruction 2
# Instruction 3
# ...
Comme dans la plupart des langages de programmation, les instructions en R se composent de deux types d'éléments fondamentaux :
- Les éléments littéraux
- Les éléments symboliques
Éléments littéraux
Les éléments littéraux sont tout simplement des éléments dans les instructions qui représentent exactement la valeur qu'ils affichent. Il s'agit d'une notion plus simple à comprendre que à expliquer, mais elle est néanmoins importante à saisir avant d'aborder les éléments symboliques.
En R il existe plusieurs types d'éléments littéraux, également appelés éléments atomiques, parmi lesquels les plus fréquents sont :
- Les nombres entiers, par exemple :
3,97,123456789, etc.
- Les nombres décimaux, par exemple :
1.34,29.781, etc.
- Les suites de caractères, délimitées habituellement par des guillemets, par exemple :
"EduTechWiki","Pas du tout d'accord","ID-12345", etc.
- Les valeurs logiques :
TRUE,FALSE(tout en majuscules et sans guillemets)
- L'absence d'un élément
NULL,NA(tout en majuscules et sans guillemets)
Éléments symboliques
Les éléments symboliques, au contraire, sont des éléments qui représentent quelque chose d'autre ; on parle souvent à ce propos de référence symbolique justement pour mettre en évidence cette fonction de représentation. On peut diviser les éléments symboliques en R en deux grandes catégories :
- Les données ou structures des données
- Les procédures ou fonctions
Références à des données ou structures de données
La manière la plus utilisée pour créer une référence symbolique à des données ou structures des données consiste à utiliser le symbole d'affectation <-, comme par exemple dans le code suivant :
# Affectation/Déclaration d'une référence symbolique avec le symbole d'affectation "<-"
country <- "Switzerland"
Avec cette instruction nous avons créé une liaison (i.e. binding en anglais) entre la référence symbolique country et la valeur littérale, constituée par une suite de caractères, "Switzerland". Métaphoriquement, c'est comme si on avait lié un fil entre le mot country et la suite de caractères "Switzerland". Chaque fois qu'on tire le mot country, nous pouvons récupérer ce qui est de l'autre côté du fil, dans ce cas "Switzerland". Cet exemple nous permet de proposer déjà quelques considérations préliminaire sur ce mécanisme :
- L'association entre référence symbolique et la valeur est arbitraire.
- D'un point de vue formel, les associations suivantes sont tout à fait valables :
country <- "Geneva" country <- FALSE country <- 3.14
- L'interprète R doit pouvoir discriminer entre une référence symbolique est une valeur littérale
- Pour cette raison, les références symboliques doivent respecter certaines caractéristiques, comme par exemple :
- On ne peut pas utiliser des nombres entiers ou décimaux comme noms des références symboliques, car cela créerait un mis-match de ce type :
# Code NON valable 13 <- 17
- Les références symboliques ne peuvent contenir des espaces, autrement elles seraient traitées comme deux références symboliques différentes :
# Code NON valable my country <- "Switzerland"
- Elles ne peuvent pas contenir le tiret haut
-, car ceci correspond à l'opération de la soustraction, et l'interprète essayerait ainsi de soustraire le deuxième mot du premier :# Code NON valable my-country <- "Switzerland"
- Les références symboliques peuvent se composer de tous les caractères alphanumériques et peuvent utiliser également le tiret bas et le point, à condition de ne pas commencer avec un chiffre ou le tiret bas. Il est de bonne pratique d'utiliser une stratégie cohérente pour les références symboliques composées de plusieurs mots, par exemple :
# "Snake case" : séparation par tiret bas (ou underscore) en utilisant que des minuscules my_beloved_country <- "Switzerland" # "Camel case" : utilisation d'une lettre majuscule à partir du deuxième mot composé myBelovedCountry <- "Switzerland"
- Les références symboliques peuvent se référer à d'autres références symboliques.
- Dans ce cas, c'est comme si vous attachez un fil à un autre fil et ainsi de suite. Le risque, très élevé d'ailleurs dans des analyses complexes, est de finir par emmêler les fils et se désorienter parmi les différentes références symboliques :
first_country <- "Switzerland" second_country <- "France" my_beloved_country <- first_country
Lorsque les données partagent une relation sémantique entre elles, elles peuvent s'organiser en structures de données. Parmi ce structures on retrouve :
- Les vecteurs
- Les matrices
- Les data frames
- Les listes
Les différences techniques entre ces structures dépassent les objectifs introductifs de cet article, mais il est néanmoins important de sensibiliser au fait que selon le type de structure utilisée, il sera possible (ou impossible) d'effectuer certaines procédures ou fonctions, et que certaines structures n'acceptent que des éléments du même type (e.g. que des suites de caractères ou que des chiffres).
Le code suivant associe à la référence symbolique my_beloved_countries un vecteur composé par 3 suite de caractères :
my_beloved_countries <- c("Switzerland", "France", "Italy")
La notation c() est un exemple de procédure ou de fonction que nous allons aborder dans le point suivant.
Références à des procedures ou fonctions
L'autre catégorie d'éléments symboliques est représentée par les procedures, également appelées routines, ou plus simplement identifiées en tant que fonctions. Si les données et structures de données jouent un rôle principalement statique, de stockage de l'information, les fonctions servent à manipuler l'information, afin de passer progressivement à des stades qui s'approchent au résultat souhaité.
En raison de leur caractère dynamique, les fonctions ont un cycle de vie qui se compose de deux stades :
- Une phase de définition de la fonction, dans laquelle on définit ce que la fonction est censée faire
- Une phase d'invocation de la fonction, dans laquelle la fonction est intégrée dans la suite d'instructions
La phase de définition est unique, c'est-à-dire qu'elle est faite une fois seulement, en amont de l'invocation ; l'invocation, au contraire, peut se faire à plusieurs reprises.
# Définition d'une référence symbolique à une procedure
my_procedure <- function () {
# Do something
}
# Invocation de la fonction à plusieurs reprises
my_procedure()
my_procedure()
my_procedure()
Comme on le verra plus bas dans la page, R possède déjà plusieurs fonctions qui ont été définies en amont par les créateurs du langage, et d'autres encore sont disponibles dans des paquets externes. Il est tout à fait possible d'utiliser R sans faire recours à la phase de définition des fonctions, mais en se limitant à invoquer des fonctions déjà définies. Même dans ce cas, néanmoins, il est important de bien saisir le caractère symbolique des fonctions qui suit le même principe des références symboliques aux données : l'association entre le nom de la fonction et son comportement est arbitraire, mais le nom de la fonction doit respecter les mêmes contraintes, afin que l'interprète de R puisse l'identifier en tant que telle.
L'un des intérêts principaux des fonctions et la manipulation des éléments littéraux, directement ou indirectement à travers les références symboliques. Le code suivant illustre ce principe à travers la fonction mean() qui accepte des données de type numérique en tant que Input et affiche la moyenne arithmétique en tant que Output :
# Fonction invoquée avec de nombres littéraux
mean(c(1, 2, 3, 4, 5, 6))
# Fonction invoquée avec une référence symbolique
my_numbers <- c(1, 2, 3, 4, 5, 6)
mean(my_numbers)
Combiner éléments littéraux et symboliques
L'intérêt principale du codage réside dans la possibilité de combiner les éléments littéraux et symboliques. Par exemple, dans une analyse standard dans le cadre des sciences sociales, on peut identifier les étapes suivantes :
# 1. Créer une référence symbolique à des données et utiliser une procédure pour récupérer les données depuis un fichier
my_data <- read.csv(file="my_file_with_data.csv", header=TRUE, sep=",")
# 2. Manipuler les données à l'aide d'autres procedures pour atteindre les finalités souhaitées
print(my_data)
summary(my_data)
Même sans connaître les détails du codage de la ligne 2, on peut néanmoins décrire son fonctionnement à l'aide des notions que nous avons vu plus haut :
- Nous créons une référence symbolique nommée
my_data - Nous utilisons une fonction appelée
read.csv()qui acceptent certains arguments, comme par exemple le chemin/nom du fichier - Ce fichier contient très probablement une structure de données, c'est-à-dire des éléments littéraux organisés d'une certaine manière, par exemple en lignes et colonnes
- Par conséquent, la référence symbolique
my_dataest maintenant liée à une structure de données littéraux que nous pouvons par la suite manipuler à travers cette même référence symbolique (e.g. lignes 5-6)
Computation : l'interprétation d'une série d'instructions
La phase de computation est celle qui ne nécessite pas d'intervention humaine, car elle est automatisée et déterminée par les inputs qui ont été données à travers les instructions. La computation se fait à travers la lecture des instructions et leur évaluation. Bien que la lecture des instructions se fasse de manière linéaire, de gauche à droite et du haut vers le bas, l'évaluation du code suit des règles de précédence qui sont établi par le langage de programmation. Par exemple dans le mécanisme d'affectation de la référence symbolique sum_the_numbers, l'addition des deux chiffres est faite en amont de l'affectation :
sum_the_numbers <- 10 + 20
De cette manière, sum_the_numbers équivaut à 30. S'il n'y avait pas de mécanisme de précédence dans l'évaluation du code, on aurait eu d'abord l'affectation à 10, et ensuite l'addition de 20 en dehors de l'affectation :
sum_the_numbers <- 10
sum_the_numbers + 20
Dans ce cas, la valeur de sum_the_numbers serait restée à 10, et l'addition suivante de 20 n'aurait pas été retenue par la référence symbolique.
L'un des enjeux majeurs dans la programmation à travers du code est celui de définir l'évaluation des étapes intermédiaires dans le bon ordre, afin que les procedures suivantes puissent s'appuyer sur les étapes précédentes. Si ceci peut sembler élémentaire dans le contexte d'un nombre limité d'instructions, cet aspect devient primordiale lors que l'analyse est étalée dans un grand nombre d'instructions. D'ailleurs, cet aspect est encore plus déterminant lorsque parmi les instructions figurent des procedures dont le temps d'exécution ne peut pas être prévu à l'avance, comme par exemple la récupération d'informations depuis le web.
Computation et environnement

La phase de computation est étroitement liée à l'un des concepts clés de l'utilisation de R : l'environnement. Si on se réfère souvent aux algorithmes (i.e. les instructions) comme les étapes dans une recette de cuisine, dans la même similitude l'environnement correspond à l'état de la cuisine, et de ses éléments, à un moment donné dans le temps. En d'autres termes, lorsque les instructions se réfèrent à des éléments, ces éléments doivent :
- Exister dans l'environnement pour que l'interprète puisse les identifier, les récupérer et les intégrer dans la computation
- Refléter leur état au moment précis dans lequel ils sont utilisés, c'est-à-dire refléter les éventuelles manipulations qui ont été apportées à l'élément par des instructions précédentes (e.g. même si on se réfère toujours à la viande dans une recette de cuisine, elle ne sera pas dans le même état au début de la recette, quand elle sort du frigo, ou à la fin, après qu'elle a été cuite).
L'utilisation de RStudio est très utile pour l'explication de ce concept, car le logiciel consacre justement une partie de l'interface à l'environnement. Cette partie de l'interface (dans l'image a côté), qui se trouve habituellement sur le côté droit, affiche les éléments qui font partie de l'environnement après l'exécution des instructions. Au début, lorsque aucune instruction n'a pas encore été exécutée, l'environnement global résulte vide (même si on verra plus bas que ce n'est pas vraiment le cas).
Instructions et environnement
Le rapport entre instructions et environnement peut se faire de 4 manières :
- Aucune relation entre les instructions et l'environnement
- C'est le cas le moins intéressant et qui est rarement utilisé dans la réalité, mais il est utile de le citer au niveau conceptuel. Vous avez ce cas de figure lorsque vos instructions ne contiennent aucun référence symbolique, comme par exemple dans un calcul entre chiffres littéraux :
146 + 173
- Si vous lancez cette instruction, vous allez obtenir le résultat (
[1] 319), mais l'environnement ne sera pas concerné. Vous pouvez en avoir la confirmation en regardant le panneau Environment en RStudio qui n'aura pas changé.
- Modifier l'état de l'environnement
- Les instructions agissent sur l'environnement en modifiant son contenu. Par exemple :
- Ajouter un élément à l'environnement à travers l'affectation d'une nouvelle référence symbolique
new_element_in_environment <- "I have been added to the environment"
- Lorsque vous exécutez cette instruction, vous pouvez bien noter que dans le panneau Environment de RStudio apparaît maintenant un nouveau élément.
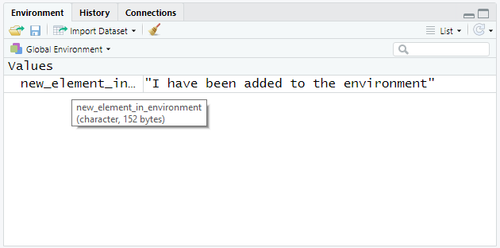
Nouveau élément dans l'environnement
- Mettre à jour la valeur d'un élément dans l'environnement
new_element_in_environment <- c(10, 20, 30, 40, 50)
- Si l'élément existe déjà, sa valeur peut être changée dans n'importe quel autre type de donnée. Dans ce cas, par exemple, la référence
new_element_in_environmentest passée d'une suite de caractères à un vecteur numérique. 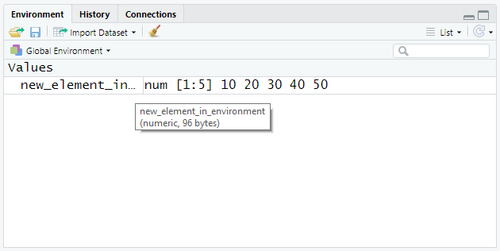
Les éléments dans l'environnement peuvent être affectés à des nouvelles valeurs.
- Supprimer un élément de l'environnement
rm(new_element_in_environment)
- Les éléments peuvent être supprimés, par exemple en utilisant la fonction
rm(), abbreviation de remove. De cette manière, il ne sont plus disponibles dans l'environnement et la mémoire qui leur avait été dédiée est libérée.
- Récupérer des informations depuis l'environnement
- Cette opération est plus étroitement liée à la phase de Output que nous verrons plus bas, mais elle figure également ici car on peut la combiner avec de la computation, par exemple dans l'exemple suivant :
# Créer une référence symbolique à un vecteur numérique avec des notes my_grades <- c(5.5, 4.25, 6, 5.75, 4) # Récupérer la note la plus élevée max(my_grades)
- La fonction
max(my_grade)récupère depuis l'environnement les informations stockées dans la référence symboliquemy_grade, mais ne modifie pas son contenu, ni apporte d'autres changements à l'environnement.
- Récupérer des informations depuis l'environnement et les utiliser pour modifier l'environnement
- Il s'agit de la stratégie la plus puissante, car elle combine les deux précédentes. L'environnement est adapté progressivement en s’étayant sur l'information précédente pour obtenir la suivante. C'est en général de cette manière que les algorithmes sont construits. D'autre part, c'est également la procedure la plus complexe, car elle nécessite de faire recours à la pensée computationnelle afin de pouvoir réduire la complexité du processus à des instructions plus simples.


Paquets et environnement

Un autre élément qui est utile à comprendre l'environnement est le concept de paquet, ou package en anglais.
Plus haut dans la page, nous avons fait référence au fait que l'environnement global de R, au début, est vide, mais en spécifiant que ceci ne correspond pas vraiment à la vérité. On peut maintenant mieux expliciter cet aspect, qui nous permettra également de comprendre pourquoi R est considéré, à la base, un environnement pour l'analyse statistique. Pour ce faire, nous allons encore une fois faire recours à la partie de l'interface consacrée à l'environnement de RStudio.
À côté du label Global environment s'affiche une flèche vers le bas. Lorsqu'on clique sur cette flèche, on obtient une liste d'éléments qui partagent ce format: package:nom-du-paquet. Chacun de ces éléments de la liste représente justement un paquet qui est disponible out of the box lorsque vous démarrez R. Comme vous pouvez le noter depuis l'image à côté, le premier paquet s'appelle package:stats. Si vous cliquez sur son nom, vous obtenez la liste de tous les éléments qui composent le paquet. Ces éléments sont catégorisé de différentes manières, par exemple le paquet stats propose des Values et des Functions. La différence entre ces éléments n'est pas fondamentale au niveau conceptuel ; l'important est plutôt de retenir qu'il s'agit de références symboliques que nous pouvons intégrer directement dans nos instructions, car l'environnement est conscient de leurs existence et, lorsqu'ils les rencontrent dans l'exécution des instructions, il peut les reconnaître et les intégrer dans la computation.
La présence du paquet stats, de plus, rend explicite pourquoi R est considéré un environnement pour les analyses statiques. En effet, ce paquet contient des fonctions, comme par exemple aov(), acronyme de Analysis of Variance (Analyse de la variance), qui sont normalement utilisées dans l'analyse statistique. D'autres paquets disponibles out of the box incluent par exemple des jeux des données (package:datasets) ou des fonctionnalités graphiques (package:graphics). La fonction mean(), que nous avons utilisée plus haut dans la page, appartient par exemple au paquet package:base. On retrouve dans cet exemple le concept de référence arbitraire qui peut être facilement testée en essayant d'utiliser la fonction average() au lieu de mean() :
numbers <- c(1, 2, 3, 4, 5)
mean(numbers) # Donne le résultat 3
average(numbers) # Donne l'erreur Error in average(numbers) : could not find function "average"
La fonction average() n'est pas reconnue par l'interprète car, contrairement à mean(), elle ne fait pas partie de l'environnement.
Implémenter l'environnement avec des paquets externes
L'articulation entre environnement et paquets nous permet également d'aborder l'un des aspects les plus importants de R : l'utilisation de paquets externes. Utiliser un paquet externe revient tout simplement à peupler l'environnement avec des éléments qui ont été créés par quelqu'un d'autres, et que nous pouvons par la suite utiliser dans notre propre code. Ce mécanisme se fait en deux parties :
- Installer le nouveau paquet sur la machine/environnement de travail que nous utilisons
- Cette opération est à effectuer normalement seulement une fois par machine/environnement de travail, même s'il peut s'avèrer nécessaire de la répéter par exemple suite à l'installation d'une nouvelle version de R ou des problèmes de compatibilité. L'installation peut s'effectuer de différentes manières, notamment :
- À travers du code :
# Installer le paquet "ggplot2" install.packages("ggplot2")
- À travers le menu de RStudio :
Tools > Install packages. Il suffit à ce moment de saisir les premières lettre du paquets pour obtenir une liste de suggestions. Vous pouvez noter que, une fois lancé la commande, la console de RStudio affiche tout simplement l'équivalent du code vu plus haut. - À travers l'onglet
Packagesde l'interface graphique de RStudio qui dispose d'un boutonInstall. Ce bouton ouvre la même fenêtre modale du point précédent et se traduit exactement dans le même code.
- À travers du code :
- Dans tous les cas, cette opération aboutit au même résultat : le code du paquet est téléchargé depuis une source externe (par exemple le dépôt officiel CRAN) et mémorisé sur la machine/environnement de travail de l'utilisateur.
- Cette opération est à effectuer normalement seulement une fois par machine/environnement de travail, même s'il peut s'avèrer nécessaire de la répéter par exemple suite à l'installation d'une nouvelle version de R ou des problèmes de compatibilité. L'installation peut s'effectuer de différentes manières, notamment :
- Charger (i.e. load en anglais) le paquet dans l'environnement global
- Cette opération doit s'effectuer à chaque fois qu'on souhaite utiliser le paquet dans la session de travail courante (voir point suivant). Encore une fois, elle peut se faire de différentes manières, même si, contrairement à l'installation ou les modalités sont plus ou moins équivalentes, pour cette phase le code est la manière la plus indiquée :
- À travers le code :
# Charger le paquet "ggplot2" (qui a été installé au préalable) library(ggplot2)
- À travers l'onglet
Packagesde l'interface graphique de RStudio, en cochant la case à côté du nom du paquet souhaité. Encore une fois, cette opération aboutit tout simplement au même code du point précédent.
- À travers le code :
- Dans les deux cas, l'opération consiste à rendre disponible à l'environnement global les éléments contenus dans le paquet. Une fois chargé le paquet, vous pouvez bien noter qu'il apparaît avec les paquets disponibles out of the box (voir image plus bas). Ceci confirme que l'environnement est conscient de son existence et que vous pouvez à ce moment utiliser les références symboliques (données et/ou fonctions) du paquet.
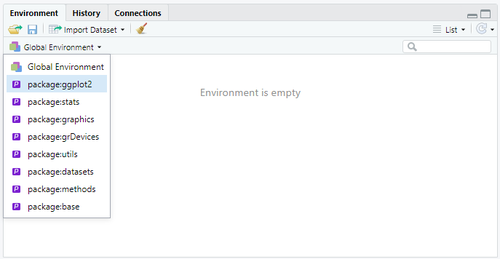
Une fois chargé le paquet, il apparaît dans la liste des paquets disponibles dans l'environnement global.
- Cette opération doit s'effectuer à chaque fois qu'on souhaite utiliser le paquet dans la session de travail courante (voir point suivant). Encore une fois, elle peut se faire de différentes manières, même si, contrairement à l'installation ou les modalités sont plus ou moins équivalentes, pour cette phase le code est la manière la plus indiquée :

Le fait que les paquets externes doivent être installés et chargés est parfois vécu comme inutile et rébarbative, surtout par des personnes s'approchant à R pour la première fois et sans une expérience similaire, par exemple, avec des plug-ins dans des logiciels ou des éléments similaires dans d'autres langages (voir par exemples les bibliothèques JavaScript). Cependant ce mécanisme est rendu indispensable par les nombreuses utilisations différentes qu'on peut faire de R, ce qui se traduit par un écosystème très large de paquets externes. Si R avait toujours à disposition tout le code nécessaire aux différentes paquets, il serait beaucoup plus lourd et beaucoup de ressources (espace et computation) seraient utilisées inutilement.
Pour éviter d'oublier de charger des paquets, il est de bonne pratique de les charger tous au début du code, un paquet par ligne :
# Charger tous les paquets nécessaires
library(...)
library(...)
library(...)
# Écrire les instructions
...
...
Computation et session

Un autre concept très important dans l'utilisation de R est le principe de session. Pour bien comprendre cet aspect, il est utile de définir deux modalités d'utilisation de R que nous pouvons placer sur un continuum entre deux pôles (voir figure à côté) :
- Programmation interactive d'une part, ce qui correspond à écrire et évaluer le code de manière progressive, ligne après ligne (ou presque), afin d'aboutir enfin au résultat souhaité ;
- Scripting automatisé de l'autre, ce qui correspond à lancer une commande qui évalue toutes les instructions sans interruption jusqu'à ce que l'ensemble du code de l'analyse a été évalué.
Lorsqu'on utilise surtout la programmation interactive, il est nécessaire de pouvoir accéder aux éléments qui font partie de l'environnement, afin de pouvoir les utiliser progressivement dans l'analyse. Comme on l'a vu plus haut, l'environnement est modifié en fonction des instructions qui sont exécutées et par conséquent son état change dans le temps.
Dans cette perspective, avec l'expérience il est de bonne pratique de créer des scripts automatisés qui déterminent ce cycle de vie du début à la fin. Cette démarche à l'avantage de pouvoir répliquer l'environnement exactement de la même manière à chaque exécution du script.
D'ailleurs, l'une des commandes les plus utilisés par les utilisateurs fréquents de R concerne justement la termination de la session courante et la création d'un nouveau cycle de vie, qui démarre avec l'environnement global vide (à l'exception des paquets qu'on a vu plus haut). Cette commande est disponible dans l'interface RStudio :
- À travers le menu
Session > Restart R - Le raccourci du clavier
Ctrl + Shift + F10pour WindowsCmd + Shift + F10sur Mac
L'utilisation de cette commande, combiné à l'écriture du code source dans des fichiers réutilisable, permet de libérer l'environnement de tout élément non répertorié dans le code (e.g. crée pour un essaie) et d'éviter par conséquent que la session ne puisse pas être reproduite exactement de la même manière dans le futur.
Computation et debug
La phase de computation est également celle dans laquelle les problèmes apparaissent, car l'interprète n'arrive pas à exécuter les instructions données à cause d'erreurs (ou bugs) dans le code. Malheureusement, les messages d'erreurs fournis par R ne sont souvent pas très clairs, ce qui n'aide pas surtout les néophytes à comprendre les raisons des interruptions de la computation.
Par exemple, l'image plus bas montre deux types d'erreurs assez fréquents dans l'utilisation de R :

- Les erreurs de syntaxe
- Il s'agit d'erreurs très fréquents qui vont interromper le script et afficher un message d'erreur. Dans l'exemple, l'interprète R ne reconnaît pas un pattern valable dans la suite
ceci est une erreur(voir explication sur les noms valides des références symboliques plus haut) et affiche par conséquent un message d'erreur.
- Il s'agit d'erreurs très fréquents qui vont interromper le script et afficher un message d'erreur. Dans l'exemple, l'interprète R ne reconnaît pas un pattern valable dans la suite
- Les instructions incomplètes
- Lorsque les instructions ne respectent pas exactement le pattern, mais n'ont pas d'erreurs syntaxique, l'interprète R les considère en tant que incomplète et par conséquent propose de pouvoir les continuer avec un
+au début de la ligne suivante. Dans l'exemple, l'instructionmean(c(1,2,3)manque d'une)finale, c'est pour cette raison que la ligne de commande propose le+. Si on ajoute la parenthèse manquante, on peut compléter l'instruction.
- Lorsque les instructions ne respectent pas exactement le pattern, mais n'ont pas d'erreurs syntaxique, l'interprète R les considère en tant que incomplète et par conséquent propose de pouvoir les continuer avec un