|
|
| (24 versions intermédiaires par le même utilisateur non affichées) |
| Ligne 1 : |
Ligne 1 : |
| | {{tutoriel |
| | |fait_partie_du_cours=Python |
| | |statut=Terminé |
| | |difficulté=intermédiaire |
| | |derniere_modif=2018/11/16 |
| | |prérequis=Python |
| | }} |
| | Ce script nécessite python3+ et la librairie pandas. Il permet de passer d'un tableau de données de dyades structurées par individus à une structure par dyades. |
|
| |
|
| Ce script python est destiné à convertir un fichier de données dyadiques d'une structure individuelle à une structure dyadique. Il nécessite python3+ et la librairie pandas.
| | Pour installer pandas à partir de pip dans l'invite de commande/terminal : <source>python -m pip install –upgrade pandas</source> |
|
| |
|
| Pour installer pandas : python -m pip install --upgrade pandas dans le terminal.
| | <br> |
|
| |
|
| Structure individuelle : | | Structure individuelle : |
|
| |
|
| 
| | [[File:Attachment-dyadic_individual_structure.gif|Individual structure]] |
|
| |
|
| Structure dyadique : | | Structure dyadique : |
|
| |
|
| 
| | [[Fichier:Dyadic structure.gif|Dyadic structure]] |
|
| |
|
| # <b>Code</b>
| | = <b>Code</b> = |
|
| |
|
| | | <source lang="python">#!/usr/bin/env python |
| ```python
| |
| #!/usr/bin/env python | |
| # -*- coding: utf-8 -*- | | # -*- coding: utf-8 -*- |
| import os | | import os |
| import pandas as pd | | import pandas as pd</source> |
| ```
| | <b>Spécifier le chemin d'accès de votre dossier</b> |
| | |
| <b>Indiquer le chemin du dossier contenant le fichier .csv à la place de path (entre guillemets)</b>
| |
| | |
| | |
| ```python
| |
| os.chdir('D:\\Google Drive\\1-These\\13-EATMINT2\\Analyses\\Questionnaires')
| |
| ```
| |
| | |
| <b>Indiquer le nom du fichier .csv à la place de file (entre guillemets)</b> | |
| | |
| | |
| ```python
| |
| df1 = pd.read_csv('questionnaire_raw_data_individual_structure.csv',sep=';')
| |
| ```
| |
| | |
| Voir les premières lignes de votre fichier :
| |
| | |
| | |
| ```python
| |
| df1.head()
| |
| ```
| |
| | |
| | |
| | |
| | |
| <div>
| |
| <style scoped>
| |
| .dataframe tbody tr th:only-of-type {
| |
| vertical-align: middle;
| |
| }
| |
| | |
| .dataframe tbody tr th {
| |
| vertical-align: top;
| |
| }
| |
|
| |
|
| .dataframe thead th {
| | <source lang="python">os.chdir('path')</source> |
| text-align: right;
| | <b>Préciser le nom de votre fichier .csv. Le fichier .csv doit être sauvegardé avec un encodage utf-8 pour que les caractères accentués soient pris en compte</b> |
| }
| |
| </style>
| |
| <table border="1" class="dataframe">
| |
| <thead>
| |
| <tr style="text-align: right;">
| |
| <th></th>
| |
| <th>Dyade</th>
| |
| <th>Sujet</th>
| |
| <th>Sexe</th>
| |
| <th>Condition</th>
| |
| <th>Score Raven</th>
| |
| <th>Activation_soi</th>
| |
| <th>Anxiété_soi</th>
| |
| <th>Colère_soi</th>
| |
| <th>Contrôle_soi</th>
| |
| <th>Déception_soi</th>
| |
| <th>...</th>
| |
| <th>Mon partenaire mettait nos différences en évidence</th>
| |
| <th>Mon partenaire n'était pas réceptif à ce que je lui disais</th>
| |
| <th>Mon partenaire n'était pas très sûr de lui</th>
| |
| <th>Mon partenaire ne se fiait pas à ce que je lui proposais</th>
| |
| <th>Mon partenaire ne semblait pas enthousiasmé par nos échanges</th>
| |
| <th>Mon partenaire se comportait comme s'il était plus fort que moi</th>
| |
| <th>Mon partenaire se montrait aimable envers moi</th>
| |
| <th>Mon partenaire se montrait autant intéressé par la construction d'une bonne entente entre nous que par la résolution de la tâche</th>
| |
| <th>Mon partenaire se montrait tendu et\ou agacé</th>
| |
| <th>Mon partenaire voulait rester coller à l'objectif principal de la tâche</th>
| |
| </tr>
| |
| </thead>
| |
| <tbody>
| |
| <tr>
| |
| <th>0</th>
| |
| <td>1</td>
| |
| <td>1</td>
| |
| <td>H</td>
| |
| <td>CBVB</td>
| |
| <td>20.0</td>
| |
| <td>4</td>
| |
| <td>1.0</td>
| |
| <td>3</td>
| |
| <td>2.0</td>
| |
| <td>6.0</td>
| |
| <td>...</td>
| |
| <td>1.0</td>
| |
| <td>2.0</td>
| |
| <td>5.0</td>
| |
| <td>3</td>
| |
| <td>1</td>
| |
| <td>1.0</td>
| |
| <td>7</td>
| |
| <td>6</td>
| |
| <td>1</td>
| |
| <td>3.0</td>
| |
| </tr>
| |
| <tr>
| |
| <th>1</th>
| |
| <td>1</td>
| |
| <td>2</td>
| |
| <td>H</td>
| |
| <td>CBVB</td>
| |
| <td>22.0</td>
| |
| <td>4</td>
| |
| <td>1.0</td>
| |
| <td>1</td>
| |
| <td>2.0</td>
| |
| <td>5.0</td>
| |
| <td>...</td>
| |
| <td>1.0</td>
| |
| <td>1.0</td>
| |
| <td>2.0</td>
| |
| <td>1</td>
| |
| <td>1</td>
| |
| <td>1.0</td>
| |
| <td>7</td>
| |
| <td>7</td>
| |
| <td>1</td>
| |
| <td>6.0</td>
| |
| </tr>
| |
| <tr>
| |
| <th>2</th>
| |
| <td>2</td>
| |
| <td>1</td>
| |
| <td>H</td>
| |
| <td>CBVH</td>
| |
| <td>19.0</td>
| |
| <td>5</td>
| |
| <td>2.0</td>
| |
| <td>3</td>
| |
| <td>4.0</td>
| |
| <td>2.0</td>
| |
| <td>...</td>
| |
| <td>2.0</td>
| |
| <td>1.0</td>
| |
| <td>2.0</td>
| |
| <td>1</td>
| |
| <td>1</td>
| |
| <td>1.0</td>
| |
| <td>7</td>
| |
| <td>7</td>
| |
| <td>4</td>
| |
| <td>7.0</td>
| |
| </tr>
| |
| <tr>
| |
| <th>3</th>
| |
| <td>2</td>
| |
| <td>2</td>
| |
| <td>H</td>
| |
| <td>CBVH</td>
| |
| <td>17.0</td>
| |
| <td>4</td>
| |
| <td>3.0</td>
| |
| <td>1</td>
| |
| <td>5.0</td>
| |
| <td>1.0</td>
| |
| <td>...</td>
| |
| <td>1.0</td>
| |
| <td>2.0</td>
| |
| <td>2.0</td>
| |
| <td>3</td>
| |
| <td>1</td>
| |
| <td>5.0</td>
| |
| <td>6</td>
| |
| <td>7</td>
| |
| <td>2</td>
| |
| <td>4.0</td>
| |
| </tr>
| |
| <tr>
| |
| <th>4</th>
| |
| <td>3</td>
| |
| <td>1</td>
| |
| <td>H</td>
| |
| <td>CHVB</td>
| |
| <td>23.0</td>
| |
| <td>4</td>
| |
| <td>6.0</td>
| |
| <td>2</td>
| |
| <td>3.0</td>
| |
| <td>6.0</td>
| |
| <td>...</td>
| |
| <td>5.0</td>
| |
| <td>1.0</td>
| |
| <td>4.0</td>
| |
| <td>1</td>
| |
| <td>1</td>
| |
| <td>1.0</td>
| |
| <td>6</td>
| |
| <td>7</td>
| |
| <td>4</td>
| |
| <td>5.0</td>
| |
| </tr>
| |
| </tbody>
| |
| </table>
| |
| <p>5 rows × 125 columns</p>
| |
| </div> | |
|
| |
|
| | <source lang="python">df1 = pd.read_csv('fichier.csv',sep=';')</source> |
| | <b>Supprimer les colonnes pour lesquelles vous ne souhaitez pas restructurer les données</b> |
|
| |
|
| | <source lang="python">data = df1.drop(['Dyade','Sujet','Sexe','Condition'], axis = 1)</source> |
| | <b>Mettre les noms de colonnes dans une liste</b> |
|
| |
|
| <b>Supprimer les colonnes pour lesquelles le changement de structure ne s'applique pas</b> | | <source lang="python">variables = data.columns</source> |
| | |
| | |
| ```python
| |
| data = df1.drop(['Dyade','Sujet','Sexe','Condition'], axis = 1)
| |
| data.head()
| |
| ```
| |
| | |
| | |
| | |
| | |
| <div>
| |
| <style scoped>
| |
| .dataframe tbody tr th:only-of-type {
| |
| vertical-align: middle;
| |
| }
| |
| | |
| .dataframe tbody tr th {
| |
| vertical-align: top;
| |
| }
| |
| | |
| .dataframe thead th {
| |
| text-align: right;
| |
| }
| |
| </style>
| |
| <table border="1" class="dataframe">
| |
| <thead>
| |
| <tr style="text-align: right;">
| |
| <th></th>
| |
| <th>Score Raven</th>
| |
| <th>Activation_soi</th>
| |
| <th>Anxiété_soi</th>
| |
| <th>Colère_soi</th>
| |
| <th>Contrôle_soi</th>
| |
| <th>Déception_soi</th>
| |
| <th>Désespoir_soi</th>
| |
| <th>Ennui_soi</th>
| |
| <th>Espoir_soi</th>
| |
| <th>Fierté_soi</th>
| |
| <th>...</th>
| |
| <th>Mon partenaire mettait nos différences en évidence</th>
| |
| <th>Mon partenaire n'était pas réceptif à ce que je lui disais</th>
| |
| <th>Mon partenaire n'était pas très sûr de lui</th>
| |
| <th>Mon partenaire ne se fiait pas à ce que je lui proposais</th>
| |
| <th>Mon partenaire ne semblait pas enthousiasmé par nos échanges</th>
| |
| <th>Mon partenaire se comportait comme s'il était plus fort que moi</th>
| |
| <th>Mon partenaire se montrait aimable envers moi</th>
| |
| <th>Mon partenaire se montrait autant intéressé par la construction d'une bonne entente entre nous que par la résolution de la tâche</th>
| |
| <th>Mon partenaire se montrait tendu et\ou agacé</th>
| |
| <th>Mon partenaire voulait rester coller à l'objectif principal de la tâche</th>
| |
| </tr>
| |
| </thead>
| |
| <tbody>
| |
| <tr>
| |
| <th>0</th>
| |
| <td>20.0</td>
| |
| <td>4</td>
| |
| <td>1.0</td>
| |
| <td>3</td>
| |
| <td>2.0</td>
| |
| <td>6.0</td>
| |
| <td>2.0</td>
| |
| <td>5</td>
| |
| <td>NaN</td>
| |
| <td>3</td>
| |
| <td>...</td>
| |
| <td>1.0</td>
| |
| <td>2.0</td>
| |
| <td>5.0</td>
| |
| <td>3</td>
| |
| <td>1</td>
| |
| <td>1.0</td>
| |
| <td>7</td>
| |
| <td>6</td>
| |
| <td>1</td>
| |
| <td>3.0</td>
| |
| </tr>
| |
| <tr>
| |
| <th>1</th>
| |
| <td>22.0</td>
| |
| <td>4</td>
| |
| <td>1.0</td>
| |
| <td>1</td>
| |
| <td>2.0</td>
| |
| <td>5.0</td>
| |
| <td>2.0</td>
| |
| <td>1</td>
| |
| <td>5.0</td>
| |
| <td>2</td>
| |
| <td>...</td>
| |
| <td>1.0</td>
| |
| <td>1.0</td>
| |
| <td>2.0</td>
| |
| <td>1</td>
| |
| <td>1</td>
| |
| <td>1.0</td>
| |
| <td>7</td>
| |
| <td>7</td>
| |
| <td>1</td>
| |
| <td>6.0</td>
| |
| </tr>
| |
| <tr>
| |
| <th>2</th>
| |
| <td>19.0</td>
| |
| <td>5</td>
| |
| <td>2.0</td>
| |
| <td>3</td>
| |
| <td>4.0</td>
| |
| <td>2.0</td>
| |
| <td>1.0</td>
| |
| <td>1</td>
| |
| <td>3.0</td>
| |
| <td>5</td>
| |
| <td>...</td>
| |
| <td>2.0</td>
| |
| <td>1.0</td>
| |
| <td>2.0</td>
| |
| <td>1</td>
| |
| <td>1</td>
| |
| <td>1.0</td>
| |
| <td>7</td>
| |
| <td>7</td>
| |
| <td>4</td>
| |
| <td>7.0</td>
| |
| </tr>
| |
| <tr>
| |
| <th>3</th>
| |
| <td>17.0</td>
| |
| <td>4</td>
| |
| <td>3.0</td>
| |
| <td>1</td>
| |
| <td>5.0</td>
| |
| <td>1.0</td>
| |
| <td>2.0</td>
| |
| <td>1</td>
| |
| <td>7.0</td>
| |
| <td>5</td>
| |
| <td>...</td>
| |
| <td>1.0</td>
| |
| <td>2.0</td>
| |
| <td>2.0</td>
| |
| <td>3</td>
| |
| <td>1</td>
| |
| <td>5.0</td>
| |
| <td>6</td>
| |
| <td>7</td>
| |
| <td>2</td>
| |
| <td>4.0</td>
| |
| </tr>
| |
| <tr>
| |
| <th>4</th>
| |
| <td>23.0</td>
| |
| <td>4</td>
| |
| <td>6.0</td>
| |
| <td>2</td>
| |
| <td>3.0</td>
| |
| <td>6.0</td>
| |
| <td>2.0</td>
| |
| <td>1</td>
| |
| <td>2.0</td>
| |
| <td>5</td>
| |
| <td>...</td>
| |
| <td>5.0</td>
| |
| <td>1.0</td>
| |
| <td>4.0</td>
| |
| <td>1</td>
| |
| <td>1</td>
| |
| <td>1.0</td>
| |
| <td>6</td>
| |
| <td>7</td>
| |
| <td>4</td>
| |
| <td>5.0</td>
| |
| </tr>
| |
| </tbody>
| |
| </table>
| |
| <p>5 rows × 121 columns</p>
| |
| </div>
| |
| | |
| | |
| | |
| <b>Mettre les noms des colonnes dans une variable</b>
| |
| | |
| | |
| ```python
| |
| variables = data.columns
| |
| ```
| |
| | |
| <b>Créer un nouveau tableau de données</b> | | <b>Créer un nouveau tableau de données</b> |
|
| |
|
| | <source lang="python">new_data = pd.DataFrame()</source> |
| | <b>Pour chaque colonne, mettre les valeur paires dans p1 et impaires dans p2. Attribuer le même index à chaque colonne. Ajouter les colonnes renommées dans le nouveau tableau de données</b> |
|
| |
|
| ```python
| | <source lang="python">for i in variables: |
| new_data = pd.DataFrame()
| |
| ```
| |
| | |
| <b>Pour chaque colonne, mettre dans p1 les valeurs paires et dans p2 les valeurs p2.
| |
| Donner un index identique pour p1 et p2.
| |
| Ajouter les deux colonnes à la suite dans le tableau de données</b>
| |
| | |
| | |
| ```python
| |
| for i in variables: | |
| p1 = data[i].iloc[::2] | | p1 = data[i].iloc[::2] |
| p1.index = range(1,len(p1)+1) | | p1.index = range(1,len(p1)+1) |
| Ligne 427 : |
Ligne 55 : |
| | | |
| new_data[v1] = p1 | | new_data[v1] = p1 |
| new_data[v2] = p2 | | new_data[v2] = p2</source> |
| ```
| | <b>Exporter le .csv restructuré</b> |
| | |
| | |
| ```python
| |
| new_data.head()
| |
| ```
| |
| | |
| | |
| | |
| | |
| <div>
| |
| <style scoped>
| |
| .dataframe tbody tr th:only-of-type {
| |
| vertical-align: middle;
| |
| }
| |
| | |
| .dataframe tbody tr th {
| |
| vertical-align: top;
| |
| }
| |
| | |
| .dataframe thead th {
| |
| text-align: right;
| |
| }
| |
| </style>
| |
| <table border="1" class="dataframe">
| |
| <thead>
| |
| <tr style="text-align: right;">
| |
| <th></th>
| |
| <th>Score Raven_p1</th>
| |
| <th>Score Raven_p2</th>
| |
| <th>Activation_soi_p1</th>
| |
| <th>Activation_soi_p2</th>
| |
| <th>Anxiété_soi_p1</th>
| |
| <th>Anxiété_soi_p2</th>
| |
| <th>Colère_soi_p1</th>
| |
| <th>Colère_soi_p2</th>
| |
| <th>Contrôle_soi_p1</th>
| |
| <th>Contrôle_soi_p2</th>
| |
| <th>...</th>
| |
| <th>Mon partenaire se comportait comme s'il était plus fort que moi_p1</th>
| |
| <th>Mon partenaire se comportait comme s'il était plus fort que moi_p2</th>
| |
| <th>Mon partenaire se montrait aimable envers moi_p1</th>
| |
| <th>Mon partenaire se montrait aimable envers moi_p2</th>
| |
| <th>Mon partenaire se montrait autant intéressé par la construction d'une bonne entente entre nous que par la résolution de la tâche_p1</th>
| |
| <th>Mon partenaire se montrait autant intéressé par la construction d'une bonne entente entre nous que par la résolution de la tâche_p2</th>
| |
| <th>Mon partenaire se montrait tendu et\ou agacé_p1</th>
| |
| <th>Mon partenaire se montrait tendu et\ou agacé_p2</th>
| |
| <th>Mon partenaire voulait rester coller à l'objectif principal de la tâche_p1</th>
| |
| <th>Mon partenaire voulait rester coller à l'objectif principal de la tâche_p2</th>
| |
| </tr>
| |
| </thead>
| |
| <tbody>
| |
| <tr>
| |
| <th>1</th>
| |
| <td>20.0</td>
| |
| <td>22.0</td>
| |
| <td>4</td>
| |
| <td>4</td>
| |
| <td>1.0</td>
| |
| <td>1.0</td>
| |
| <td>3</td>
| |
| <td>1</td>
| |
| <td>2.0</td>
| |
| <td>2.0</td>
| |
| <td>...</td>
| |
| <td>1.0</td>
| |
| <td>1.0</td>
| |
| <td>7</td>
| |
| <td>7</td>
| |
| <td>6</td>
| |
| <td>7</td>
| |
| <td>1</td>
| |
| <td>1</td>
| |
| <td>3.0</td>
| |
| <td>6.0</td>
| |
| </tr>
| |
| <tr>
| |
| <th>2</th>
| |
| <td>19.0</td>
| |
| <td>17.0</td>
| |
| <td>5</td>
| |
| <td>4</td>
| |
| <td>2.0</td>
| |
| <td>3.0</td>
| |
| <td>3</td>
| |
| <td>1</td>
| |
| <td>4.0</td>
| |
| <td>5.0</td>
| |
| <td>...</td>
| |
| <td>1.0</td>
| |
| <td>5.0</td>
| |
| <td>7</td>
| |
| <td>6</td>
| |
| <td>7</td>
| |
| <td>7</td>
| |
| <td>4</td>
| |
| <td>2</td>
| |
| <td>7.0</td>
| |
| <td>4.0</td>
| |
| </tr>
| |
| <tr>
| |
| <th>3</th>
| |
| <td>23.0</td>
| |
| <td>21.0</td>
| |
| <td>4</td>
| |
| <td>4</td>
| |
| <td>6.0</td>
| |
| <td>4.0</td>
| |
| <td>2</td>
| |
| <td>5</td>
| |
| <td>3.0</td>
| |
| <td>3.0</td>
| |
| <td>...</td>
| |
| <td>1.0</td>
| |
| <td>1.0</td>
| |
| <td>6</td>
| |
| <td>7</td>
| |
| <td>7</td>
| |
| <td>7</td>
| |
| <td>4</td>
| |
| <td>1</td>
| |
| <td>5.0</td>
| |
| <td>7.0</td>
| |
| </tr>
| |
| <tr>
| |
| <th>4</th>
| |
| <td>21.0</td>
| |
| <td>21.0</td>
| |
| <td>4</td>
| |
| <td>4</td>
| |
| <td>3.0</td>
| |
| <td>3.0</td>
| |
| <td>2</td>
| |
| <td>3</td>
| |
| <td>5.0</td>
| |
| <td>NaN</td>
| |
| <td>...</td>
| |
| <td>5.0</td>
| |
| <td>1.0</td>
| |
| <td>7</td>
| |
| <td>6</td>
| |
| <td>6</td>
| |
| <td>7</td>
| |
| <td>1</td>
| |
| <td>2</td>
| |
| <td>6.0</td>
| |
| <td>6.0</td>
| |
| </tr>
| |
| <tr>
| |
| <th>5</th>
| |
| <td>23.0</td>
| |
| <td>22.0</td>
| |
| <td>4</td>
| |
| <td>4</td>
| |
| <td>1.0</td>
| |
| <td>2.0</td>
| |
| <td>1</td>
| |
| <td>1</td>
| |
| <td>4.0</td>
| |
| <td>2.0</td>
| |
| <td>...</td>
| |
| <td>4.0</td>
| |
| <td>2.0</td>
| |
| <td>7</td>
| |
| <td>6</td>
| |
| <td>7</td>
| |
| <td>7</td>
| |
| <td>1</td>
| |
| <td>2</td>
| |
| <td>5.0</td>
| |
| <td>6.0</td>
| |
| </tr>
| |
| </tbody>
| |
| </table>
| |
| <p>5 rows × 242 columns</p>
| |
| </div> | |
| | |
| | |
| | |
| <b>Exporter le fichier .csv restructuré</b> | |
|
| |
|
| | <source lang="python">new_data.to_csv('out.csv',sep=';')</source> |
|
| |
|
| ```python
| | [[category: Python]] |
| new_data.to_csv('out.csv',sep=';')
| | [[category: Programmation]] |
| ```
| | [[category: Technologies]] |
|
Restructurer un tableau de données dyadiques |
|
| ⚐ Terminé |
☸ intermédiaire |
| ⚒ 2018/11/16 |
|
Ce script nécessite python3+ et la librairie pandas. Il permet de passer d'un tableau de données de dyades structurées par individus à une structure par dyades.
Pour installer pandas à partir de pip dans l'invite de commande/terminal :
python -m pip install –upgrade pandas
Structure individuelle :

Structure dyadique :
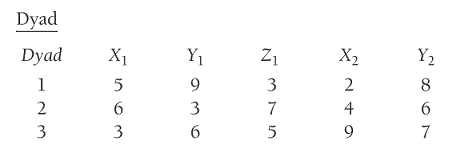
Code
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
import pandas as pd
Spécifier le chemin d'accès de votre dossier
Préciser le nom de votre fichier .csv. Le fichier .csv doit être sauvegardé avec un encodage utf-8 pour que les caractères accentués soient pris en compte
df1 = pd.read_csv('fichier.csv',sep=';')
Supprimer les colonnes pour lesquelles vous ne souhaitez pas restructurer les données
data = df1.drop(['Dyade','Sujet','Sexe','Condition'], axis = 1)
Mettre les noms de colonnes dans une liste
Créer un nouveau tableau de données
new_data = pd.DataFrame()
Pour chaque colonne, mettre les valeur paires dans p1 et impaires dans p2. Attribuer le même index à chaque colonne. Ajouter les colonnes renommées dans le nouveau tableau de données
for i in variables:
p1 = data[i].iloc[::2]
p1.index = range(1,len(p1)+1)
p2 = data[i].iloc[1::2]
p2.index = range(1,len(p2)+1)
v = i
v1 = i + '_p1'
v2 = i + '_p2'
new_data[v1] = p1
new_data[v2] = p2
Exporter le .csv restructuré
new_data.to_csv('out.csv',sep=';')

