Software localization
Disclaimer: This is the result of some note taking. The purpose of this page was to prepare some input for improving the LAMS translation strategy and toolkit. - Daniel K. Schneider 15:24, 15 June 2010 (UTC)
Introduction: What do you mean by localization ?
Software localization (or localisation) means translation of a software interface and messages to another language plus adaptation of some formats (e.g. measures, dates and currency) plus adaptation to local cultures.
Software localization is a complex process. According to Susan Armstrong, simple translation implies terminology research, editing, proofreading and page layout. Localisation, in addition, tends to involve additional activities, such as: Multilingual project management, Advice on translation strategy, Conversion of file formats in which material is held, Alignment and maintenance of translation memories, Software and online help engineering and testing, Multilingual product support.
What is software internationalization, localization, globalization ?
Localisation, i.e. the adaptation to another language and culture of software, has an impact on software engineering. In a first step, software should be internationalized (I18N), i.e. be designed in a way that it can be adapted to various languages and regions (not just one) without engineering changes to the programming logic. In principle, it is stuff that has to be done only once. However, sometimes I18N is done in stages. Often developers forget that some languages are more verbose than others. E.g. the English word "redo" is translated into the German "wiederherstellen" (4 times a long) and that means that menu items must be much wider. Also, developers forget that some languages work in other directions. For example,Arabic and Hebrew work from right-to-left (but quoted English phrases are still spelled from left to right). Chinese is vertical. More subtle points concern sorting, e.g. in some languages extended characters such as the "Ö" would be placed after the Z. A really difficult issue concerns the sentence structure. Most often, programmers work with simple placeholders. In English phrases words don't change very much if one word changes, whereas in other languages changing a single word can imply changes to other words. E.g. "important %s" can become "X important" or "Y importants. In German this becomes "wichtiger X" "wichtige Y" and "wichtiges Z". Read J. Wittner & D. Goldschmidt (2007) technical challenges and localization tools for a good summary of major internationalization issues.
Localization (L10N) means adaption of a product following the needs of a particular population in a precise geographic region. Needs include linguistic, cultural and ergonomic aspects. (Le grand dictionnaire terminologique). McKethan and White (2005) define localization as “the process of adapting an internationalized product to a specific language, script, cultural, and coded character set environment. In localization, the same semantics are preserved while the syntax may be changed.” The authors further argue that “Localization goes beyond mere translation. The user must be able to not only select the desired language, but other local conventions as well. For instance, one can select German as a language, but also Switzerland as the specific locale of German. Locale allows for national or locale-specific variations on the usage of format, currency, spell-checker, punctuation, etc., all within the single German language area.”
Gregory M. Shreve (retrieved 16:27, 21 January 2010 (UTC)) adds adaptation of "non-textual materials" like colors, logos and pictures. “Localization is the process of preparing locale-specific versions of a product and consists of the translation of textual material into the language and textual conventions of the target locale and the adaptation of non-textual materials and delivery mechanisms to take into account the cultural requirements of that locale.”
The W3C Internationalization web site also argues that
localization is often a substantially more complex issue. It can entail customization related to:
- Numeric, date and time formats
- Use of currency
- Keyboard usage
- Collation and sorting
- Symbols, icons and colors
- Text and graphics containing references to objects, actions or ideas which, in a given culture, may be subject to misinterpretation or viewed as insensitive.
- Varying legal requirements
- and many more things.
Usually, language localization extends to national subcultures. E.g. German would decline in De-de (German for Germany) and other versions for Switzerland (de-ch) and Austria (de-at), etc. National versions of a language include different words, different spellings (like "localization" vs. "localisation"), and sometimes different grammar. Conversely, a multi-lingual country like Switzerland would have German Swiss (de-ch), French Suiss (fr-ch) and Italian-Swiss (it-ch). These country-specific localizations have in common the way date/time, decimals and currency is represented. Software translators may adapt the following strategies:
- Create a generic translation for one language, e.g. fr, and then add specific local variants like fr_fr, fr_be on top of it.
- Create only one translation, e.g. fr_fr, and have users cope with it. Data/time and decimal/currency representation differences should be handled though. Most often, this is the case in free open source software.
- Sometimes, localizations only exist for major sub-cultures, e.g. a de-de and de-ch version. Other german speaking cultures like de-at (too close to German) or de-lu and de-li (too small) are not covered.
Finally, the term Software globalization (G11N), also known as National Language Support, refers to the combination of software internationalization (I18N) and localization (L10N).
Abbreviations
Let's recapitulate and explain the abbreviations for internationalization, localization and globalization. The "funny" kind of abbreviations used in the localization community are so-called numeronyms as we shall explain for the I18N.
- Internationalization, known as I18N. The 18 stands for the number of letters between the first i and last n in internationalization.
- Localization, known as l10n (or L10N) , is composed of the l of localization, followed by 10 letters (ocalizatio) and the final n of localization.
- Software globalization, known as G11N refers to: I18N + L10N
- Finally, GILT stands for Globalization, Internationalization, Localization and Translation, i.e. all matters related to localization.
Localization technology
Most localization technology used is so-called Computer-assisted translation software. In addition, localization needs specific tools to deal with editing (extracting, managing, merging) language strings in the computer code. Furthermore software localization must integrate various media, the software itself, in-context help, help systems, manuals, tutorials etc.
Issues
In this sections we shall explore some important issues. We shall stress the importance of ergonomic aspects as the #1 priority of localization. By ergonomic aspects we mean both "surface usability" (users can understand the meaning of UI interface elements and system messages) and cognitive ergonomics (user can get meaningful tasks done with the system).
Ergonomics considerations apply to both the products (software, manuals), and to the programmer and translator environments (tools, community, etc.)
Infrastructure and people
In a larger project, the list of types of participants can be quite long: E.g. Gregory M. Shreve identifies: Project managers, Translators (Generic), Localization Translators (Specialists), Terminologists, Internationalization/Localization Engineers (Software Background), Proofreaders, QA specialists, Testing engineers, Multilingual Desktop publishing specialists. These job descriptions implicitly define the kinds of tasks that are part of the localization process.
In a volunteer-based open source project we might see the following roles (that my be cumulated by the same person)
- one person to coordinate software development and interface to the translation effort
- one person to coach and coordinate software string translators and to interface with developers
- one person to coach and coordinate manual and tutorial writing, including a glossary
- volunteer translators for various translation tasks
- volunteer users that provide feedback about the UI ergonomics, spelling, in-context help, etc.
Open source projects don't have the funding to pay professional translators. This situation has disadvantages but also some advantages.
- Disadvantages: Quality of the translation, completion (untranslated strings for new versions, missing languages, etc.)
- Advantages: Meaningfulness of the translation. Often translators are users, i.e. they have know how of the tool which "normal affordable" translators do not have. According to LISA, a second interesting fact is that “the natural tendency of the localizer is to magnify the difference between [two expressions in the source language that refer to the same thing, just to be on the safe side. The result is that localizers tend to find the problems in a product that were not previously noted, problems that may well have confused users in the source language as well.”
I (16:27, 21 January 2010 (UTC)) believe that there ought to be some strategies to improve volunteer translation efforts and to profit from emerging insights. The main issues might be:
(1) Motivating people to helping to translate and to continue helping
(2) Make sure that translation is usable by providing a decent enough translation support environment
(3) Make sure to profit from translator's domain knowledge, plus inconsistencies he may detect in the original source language interface and messages.
Localization source and targets
I18N and L10N should be planned of in terms of the whole system. A software product may include:
- User documentation (includes several genres and available through several media, e.g. within the software itself, HTML, paper/PDF)
- Manuals
- Short contextual help
- Glossary / Thesaurus
- Tutorials
- ....
- Software (user)
- Menus and Icons (visual command language)
- Command languages (sometimes)
- Messages (various output)
- ....
- Software documentation
- Documentation of language constants (and other useful elements)
- Developer manuals (maybe)
All these genres may targets for localization.
Localization source refers to the kinds of text the translators have to deal with. Regarding translation of the software interface, translators often will be given a special translation files that then will be merged back into the code (see the formats section below). The same functionality can be achieved with an online translation system that relies on a database. Sometimes, translators will have to edit computer code that defines so-called constants and code syntax needs to be respected.
Regarding documentation source format, various options exist and sometimes several are used concurrently. The trend is towards single-source publishing, i.e. both authors and translators only edit one kind of text, e.g. XML-based documents, wiki pages or text processor documents. From a single source, various document types (PDF, help files, HTML, etc.) and content aggregations can be generated. In addition (this is an orthogonal option) special translation editors may show chunks of source and target text side by side. E.g. the Google translator toolkit tool discussed below works like this.
Localization may be related to development, in particular in volunteer projects. Since translation work is often done by end-users, e.g. persons with domain knowledge, there ought to be some potential for synergy that FOSS project managers and developers might try to exploit and develop. Persons writing and translating the tutorials also should make comments about the meaningfulness of system messages as well as other usability issues, and not just try to adapt the user to the system. A good focus object for starting a collective discussion would be a multi-lingual glossary/thesaurus, i.e. a coordinated terminology project.
Open source projects sometimes have to decide what (not) to translate. Often it's "good enough" to translate the essential messages and let the user cope with untranslated (English) messages for the others. E.g. translate.wiki defines a recommended process for MediaWiki translation and does fix the following priorities:
- first translate the most often used messages
- complete the core messages
- check if you should translate any optional messages
- do a consistency check (terminology, formal/informal) on your localisation
- translate special page names, magic words and namespaces on Special:AdvancedTranslate
- translate the extension messages used in Wikimedia wikis
- translate the remaining extension messages
- do a consistency check (terminology, formal/informal) on your localisation between core messages and extension messages
- start maintaining your language's localisation on a regular basis. At least once per month is recommended.
(TranslateWiki, retrieved 18:40, 4 February 2010 (UTC))
We believe that the first priority in a localization project should be a glossary, i.e. the idea that one should agree on a given terminology. This stance implies also that key terms should be understood in the same way(s) or that local differences or differences between educational communities are at least understood and addressed. This is particularly important with respect to education. Let's now look into terminology management.
Terminology management / Glossary
Terminology management refers to the fact that critical and specialized terms must be clearly defined in the source language and be linked to target languages. With respect to software localization, this should be done independently of translation of UI elements and system messages, else we may face the risk that translators only will make sure that single items are just coherently translated (e.g. the English "press" to either french "presser" or "appuyer sur") but will not necessarily reflect on the meaning of more complex concepts like "Noticeboard" (what is it good for, and how could its name broadcast its affordances. E.g. to make sure that users understand what it is good for, once could just call it "Content tool". Even a relatively simple concept like "Transition" might translate to "Verbindung" in German (meaning "link") or as "Uebergang" (meaning "going over towards there").
The Localization Industry Standards Association (LISA) defines terminology management as follows: “Quality translation relies on the correct use of specialized terms. It improves reader understanding and reduces the time and costs associated with translation. Special terminology management systems store terms and their translations, so that terms can be translated consistently. Full-featured systems go beyond simple term lookup, however, to contain information about terms, such as part of speech, alternate terms and synonyms, product line information, and usage notes. They are generally integrated with translation memory systems and word processors to improve translator productivity.” (retrieved 15:51, 27 January 2010 (UTC)).
Silvia Pavel defines terminological data as “Any information relating to a term or the concept designated. Note: The more common terminological data include the entry term, equivalents, alternate terms, definitions, contexts, sources, usage labels, and subject fields.” This can lead to rather large records, e.g. have a look at the term Apprentissage/Learning in the Termium Plus database.
Terminology management is not a simple formal question of agreeing on some ways of translating words. It's related to fundamental aspects of language use in the sense of language as action and that requires common grounding. (Clark, 1996). The translation process will and maybe must challenge the original vocabulary, i.e. point out cognitive ergonomics problems. Now we wonder if translating learning management systems into different languages could imply using a different pedagogical vocabulary. E.g. typical "french didactics" is very different from "belgian instructional design" which is different from "canadian constructivism". Two simple words illustrate what we mean: Shall we call a "student" a "learner" or a "user", does a "teacher" become an "instructor" ?
Wittner & Goldschmidt (2007) argue that “Terminology management systems should be used to maximize the consistency and relevance of terms used in both the source authoring and localization stages. These systems help manage lists of terms and give information such as context, explanations, definitions, classifications and graphics, where applicable. This information may be important for the translation of these terms and for their selection during the translation cycle.” However, as they point out, “Building a terminology management data - base is no easy task. First, all existing data and assets have to be analyzed to extract the existing terms. Although this task can be done using tools, it will inevitably entail a great deal of human work.”
In addition to a glossary that should at least cover the central terms, there should be come kind of translation memory, to help both speeding up translation and ensuring coherence.
See the example section below for some online software that can help establish common lexical items, including ways to support process of meaning negotiation between various actors.
On the code side
- Encoding
- Nowadays, projects systematically should use some form of Unicode, e.g. UTF-8.
- Space and Layout
- Space of text fields: Some languages are more verbose and one must plan for that, by using wider icons, menu items, user input fields and such. A better solution is to use a "fluid" design, i.e. the size of boxes is adapted to text it contains.
- Language messages
All output messages to the user must be defined as a kind of named constant that the programmers will use. Alternatively, it can be decided that source language strings (plus a documentation string nearby in the code) are the constants. The name of the constant should be meaningful and available to translators (since at some point here must a common way to talk about a precise translation item). Languages files should be separate for the translators (e.g. in a text file, a localization format, or through an online database).
However, we have to point out a very tricky issue here. User interface strings that are available for translation in a separate file or web interface are out of context. Ideally, the translator ought be able to press a button and somehow "see the context". Simply translating a string without knowing its precise location in the user interface will often lead to wrong translations, in particular if English is the source language. These mistakes will then have to be fixed after testing the software and this process may need several cycles. E.g. what would "Add new" mean ? "Create new", "Add the newly created" ?
The most difficult issues related to language messages have to with the fact that parts of the message will be generated at runtime. As we already explained in the short introductory paragraph on internationalization, some messages can take parameters and therefore must include placeholders for these. E.g. in the Mediawiki project messages can handle plural, gender and special grammatical transformations for agglutinative languages like Finnish, i.e. depending on how a word is used a suffix may added, plus the base can be modified. An item to be translated may have quite a lot of computer code inside.
As Bert Esselink (2000b) puts it: “it looks likely that while translators will be able and expected to increasingly focus on their linguistic tasks in localization, the bar of technical complexity will be raised considerably as well. [...] It almost seems like two worlds are now colliding: software localization with a strong focus on technical skills and technical complexity for translators on the one hand, and content localization with a strong focus on linguistic skills and technical simplicity for translators on the other.”
Reviewing / Evaluation
Localized content should be tested in target since the translators often just look at the strings but not at the context. In other words: Using the software for real or almost real by real target persons does provide good feedback. If this is not an option, the reviewer must be able to "imagine" a real situation, i.e. receive enough contextual information by trying out all features of the software.
In addition, the reviewer has to develop a list of criteria for evaluation (a quality model). Criteria may emerge from testing the software in a real situation with real tasks.
In an open-source project like LAMS that allows for frequent updating one could ask volunteer teachers to provide feedback and to ask their learners to do the same (at least write down meaningless/difficult to understand) UI elements and system messages. If this is not possible, translators should at least play all the roles: Administer the system, design both a complex and a simple sequence, use it as teacher (including the monitoring) tool, and experience it as learner. Another option could be "problem/suggestions" button to be installed optionally by the administrator in the interfaces and that would allows user to complain and make suggestions in an easy, quick and non-obtrusive way. This idea needs to be fleshed out.
Examples of software that collects user information
- The "report Broken Web Site" and "Report Web Forgery" buttons in Firefox (under the Help menu)
- The dialog you get once MS Help dialogs end up without solutions, e.g. three questions: (1) was it useful, (2) why ? and (3) additional information. Now I would like to know what kind of volume / 1000 users this generates and how it is being used.
- Some google help files have a similar interface. (1) Was this information helpful, followed by (2) Easy to understand? (3) Complete with enough details ?
- Google translate. E.g. learning activity management system translated to french "système d'apprentissage en gestion de l'activité" which is totally wrong. Users can contribute a better translation. In addition they could activate the translators toolkit, which includes glossary management, chat, etc.
Computer-assisted translation software
Today exists a rather large set of toolboxes that aim to increase the quality and the efficiency of the translation process. Some of these tools already have been introduced by example. Based on Wikipedia's Computer-assisted translation entry, we may distinguish the following types of tools. Some of these may be integrated into a single software, i.e a computer-assisted translation (CAT) tool.
(1) Spell checkers and grammar checkers:
Both can be integrated into word processors, online CMSs, programming editors or work as add-on programs
(2) Terminology managers:
This includes a whole family of tools, ranging from simple tables (entry + description) to complex glossary and thesaurus managers. Some of these exist online. A good examples is the Open Terminology Forum and Google translation tool, both discussed in this article.
Commercial programs include: LogiTerm, MultiTerm, Termex
Open source programs include:
Open source online programs:
- The Wikionary (probably not available "as is", but one could install a Mediawiki and then retrieve all the templates)
(3) Terminology databases
These include publicly available databases. Good examples:
- Wiktionary (presented below)
- Le grand dictionnaire terminologique
- Open Terminology Forum (for some restricted domains only)
(4) Full text indexers
I.e. indexing search engines that allow to formulate complex queries. Instead of searching all the Internet they will look up translation memories (see below).
(5) Concordancers
“retrieve instances of a word or an expression and their respective context in a monolingual, bilingual or multilingual corpus, such as a bitext or a translation memory.” (wikipedia)
(6) Bi-texts
A merge of source text and its translation
(7) Translation memory managers (TMM)
TMM relates to the idea that there is a database with text segments in the source language and their translations in one or more target languages. A text segment corresponds to sentences or equivalent (e.g. titles or bullet items).
In fact a TMM is specialized text editor that displays segments to be translated in one column and possible translations in another one. The translator then can reuse old translations and adapt it to the new fragment (or if there is no match, create a totally new translation.
A TMM will both improve efficiency (speed) and consistency.
(8) Software-message strings integration tools
Since translators may have difficulties to edit programmer's code, i.e. files that define constants, strings to be translated can be extracted into a format that is a bit more friendly and that can be opened in a special translation editor. See also the section on formats.
Some minimal desiderata software strings translation
Translators should "see" what they translate. This concerns several items. When translating a string, the translator should be able to see:
- The name of the constant (which must be meaningful, e.g. "modulename.mainmenu.edit" or "modulename.errormsg.upload.xxx")
- A meaningful short description. This description may include a link to a glossary.
- All other translations (languages strings) the translator understands (e.g. if I translate to German, I'd like see both the English source and the translation to French)
- (If possible) the constant displayed in the interface. I.e. the software might run in a translators' mode that would overlay somehow the constant. That of course requires some extra programming and might be achieved by changing/adding tooltips. Or an even better solution would be enabling to edit strings directly from the software interface.
Tools for consistency: When translating hundreds of strings (and the situation gets worse if it's done by several people) there should be a way to search through all terms in all modules in three ways:
- Find expressions in the target language and display both source plus an other language next to it.
- Find expressions in the source language and display the target strings next to it.
- Be able to edit and to consult a short glossary that includes the most important terms (might be combined with the general user manual). Glossary entries might be hot-linked to the translation strings interface.
- (dreaming) direct access to some online translation dictionary like the english/frenchgrand dictionnaire terminologique
See also the terminology management / glossary discussion above.
Examples of terminology and translation tools and strategies used in FOSS projects
In this section, we will look at different examples of tools and localization projects that raised our interest. Items are of a very different kind and can't be compared. But each one helped us to understand some issues and some present interesting strategic or technical solutions.
The open terminology forum
The Open Terminology forum is a freely-accessible terminology database whose content is supplied and validated by the members of a non-profit organization. According to What is it? page, “anyone who can show that they have specialized knowledge can become a member of the Forum and participate in their area of expertise, whether they are a professional, a translator, a journalist or an academic. Members can add terminology information, comment on (but not change) that contributed by others, make personal lists of selections of terms and create their personal descriptions with their own HTML links.” , retrieved 15:51, 27 January 2010 (UTC). “Each area of specialization has its own terms. The Forum is a place where these terms can be recorded, refined, discussed and validated by those concerned. As every item of information shown is personally attributed to the contributor, members can build up their reputations”

The main window shows terms in a three column layout. Terms can searched with wild-cards (* and ?). A user can then click on each of the "meaning", "English term" and "French equivalent" in order to further explore or to edit the context (with permission)
(1) Click on meaning, then Info will provide contextual information. E.g. the English term "classroom management" is not translated (should become "gestion de classe") is associated with the rather useless "for a lesson" meaning, but clicking on "for a lesson" will show a good definition plus a link.

(2) Click on a term will allow to add variants, occurrences, synonyms, translations or a comment.

(3) Click on help will show agreement among experts and some other information.
This system implements the idea that a glossary should emphasize meaning in context (glossaries are specialized and also include citations). We also liked the implementation of an experts' agreement tool.
Wiktionary
“Designed as the lexical companion to Wikipedia, the encyclopaedia project, Wiktionary has grown beyond a standard dictionary and now includes a thesaurus, a rhyme guide, phrase books, language statistics and extensive appendices. We aim to include not only the definition of a word, but also enough information to really understand it. Thus etymologies, pronunciations, sample quotations, synonyms, antonyms and translations are included.” (Main Page, retrieved 18:07, 29 January 2010 (UTC)). Advanced users may customize Wiktionary preferences. Entries can be search or looked up through various indexes.
The structure of Wiktionary entries (pages) seems to be a moving target, i.e. together with emerging needs complexity is added or page structure is modified. Also, various language variants don't look the same. I.e. the french version includes the use of icons in from of main headings (much prettier ...). Finally, exploitation of various possible headers and templates may be different in various culture.
Let's have a look at the Thesaurus discussion. The English dictionary version includes a separate thesaurus called Wikisaurus. The Germans on the other hand, do also have a small thesaurus, but globally speaking one can observe that their wiktionary seems to be more systematic, i.e. entries do include more thesaurus-like features. Here is small table we made from looking at a few entries (i.e. we don't claim it to be accurate):
In all Wiktionaries we can find:
- Synonymy – same or similar meaning
- Troponymy – manner, such as trim to cut
In the German Wiktionary we get in addition:
- Antonymy – opposite meaning
- Hyponymy – narrower meaning, subclass (Unterbegriffe)
- Hypernymy – broader meaning, superclass (Oberbegriffe)
In none we found (although it can be covered somewhat by super/subclasses)
- Meronymy – part, such as wheel of a car
- Holonymy – whole, such as car of a wheel
We may argue that the German strategy seems to see the dictionary itself as a kind of thesaurus, whereas in the English world the two have been split, although not all participants did think that this was a good strategy. Daniel K. Schneider also prefers the German "inclusive" strategy.
Let's have a look at Internet, top of english, french and german pages (Jan 2010):
- Internet compared across three Wiktionary languages (click on an image to enlarge)
-
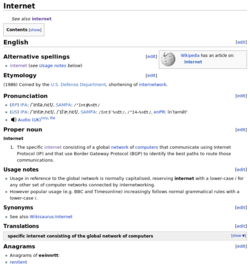
-
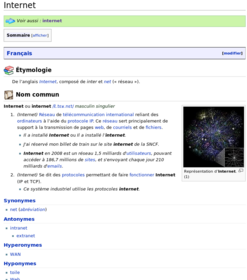
-
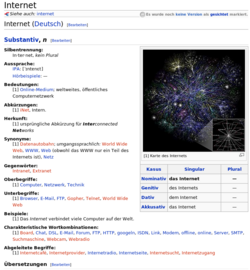



Wikionary entries are normal Mediawiki pages, but follow structuring conventions, e.g. concerning the heading structure. In addition, users must understand how to use and to find (!) templates. A Mediawiki template can be defined as some kind of extension language that allows for shortcuts, complex formatting, transclusions, etc. More precisely, Wiktionary's Index to templates provides the following definition: “Templates in Wiktionary are a convenient and consistent way of including a snippet of text in various, similar articles. Within the text of an entry, enclosing a template name inside the double curly braces {{xxx}} will instruct Wiktionary to insert right there in the entry when it is viewed the contents of the page [[Template:xxx]].”. In addition, there exist shortcuts which are a specialized types of a redirection page that can be used to get to a commonly used Wiktionary reference page more quickly. Fairly complex languages to learn that makes Daniel K. Schneider sometimes wonder whether Wikipedia and its sister projects are not the world viewed by IT-savy people...
Wiktionary pages may include translations if the spelling of the word is the same. E.g. the localisation page has both an English and a french entry. But usually, a page will refer to entries of other languages through a special template, which allows to transclude these into the page.
A minimal page typically has the following structure:
== English == ===Noun=== === References ===
The structure of a more complete entry can be illustrated by the phrase word. Its table of contents looks like this.
1. English
1.1 Pronunciation
1.2 Etymology
1.3 Noun
1.3.1 Synonyms
1.3.2 Derived terms
1.3.3 See also
1.3.4 Translations
1.4 Verb
1.4.1 Derived terms
1.4.2 Related terms
1.4.3 Translations
1.5 External links
1.6 Anagrams
2. French
2.1 Pronunciation
2.2 Noun
2.3 Anagrams
The french section is included because the word "phrase" does exist in french and means "sentence". The translation sections (one for the noun and one for the verb) includes definitions from many languages by transclusion.
Let's now examine the wiki code of an other medium-sized entry in more detail. The source wiki code of localization entry looks like this:

{{wikipedia}}
{{also|localisation}}
==English==
===Etymology===
From [[localize]] + [[-ation]];
compare French ''[[localisation#French|localisation]]''
===Alternative spellings===
* [[localisation]] (''British'')
===Noun===
{{en-noun}}
# The [[act]] of [[localize|localizing]].
# The [[state]] of being [[localized]].
====Derived terms====
* [[l10n]], [[L10n]]
* [[cerebral localization]]
* [[chromosomal localization]]
====Related terms====
* [[locale]]
* [[localism]]
* [[locality]]
* [[locate]]
====Translations====
{{trans-top|act of localizing}}
* Chinese:
:* Mandrin: {{zh-tsp||地方化|difang-hua}}
* Dutch: {{t+|nl|lokalisatie|f}}
* Finnish: {{t+|fi|lokalisoida}}, {{t+|fi|kotoistaa}}
{{trans-mid}}
[ .... contents removed .... ]
* Norwegian: {{t-|no|lokalisering|f}}
* Russian: {{t+|ru|локализация|sc=Cyrl}}
{{trans-bottom}}
{{trans-top|state of being localized}}
* Chinese:
:* Mandrin: {{zh-ts||本地化}}
* Dutch: {{t+|nl|lokalisatie|f}}
{{trans-mid}}
* Norwegian: {{t-|no|lokalisering|f}}
* Russian: [[локализованность]]
{{trans-bottom}}
{{trans-top|software engineering:
act or process of making a product suitable for use
in a particular country or region}}
* Chinese:
:* Mandrin: {{zh-ts||本地化}}
* Dutch: landelijke aanpassing
[ .... contents removed .... ]
* Russian: [[локализация]]
{{trans-bottom}}
{{checktrans-top}}
* {{ttbc|French}}: {{t+|fr|localisation|f}}
* {{ttbc|German}}: [[Lokalisation]]
* {{ttbc|Italian}}: [[localizzazione]]
{{trans-mid}}
(rookaraizeeshon)
* {{ttbc|Korean}}: [[지방화]]
* {{ttbc|Latin}}: [[localizatio]]
* {{ttbc|Portuguese}}: [[localização]]
* {{ttbc|Spanish}}: [[localización]]
* {{ttbc|Turkish}}: [[Bölge]]
{{trans-bottom}}
====See also====
* [[internationalization]] / [[i18n]]
As the reader may notice, there are many templates ({{....}}). An author may just create minimal entries or fix existing entries. Advanced authors, as we mentionned above, may choose from probably hundreds of different templates.
Let's now look at tools for discussion and user feedback.

In the English version and some but not all other language version (Jan 2010), users may leave a feedback. Users can first signal a problem, i.e. choose among:
- Good
- Bad
- Messy
- Mistake in definition
- Confusing
- Could not find the word I want
- Incomplete
- Entry has inaccurate information
- Definition is too complicated
Optionally, a user then may leave a note. It probably will append it to the discussion page. Each mediawiki page has an associated discussion page (including one for this page you are reading).
Discussion does sometimes happen on wiktionary.org. A nice and funny example is the e-dictionary's discussion page (about 10 times as long as the entry ...)
We believe that Wiktionary is an interesting project and for several reasons:
- The flexibilty of the Mediawiki infrastructure allows to cope with emerging views about what a dictionary entry should be. Indeed, from a simple dictionary it evolved into a complex one that inlcudes etymologies, pronunciations, sample quotations, synonyms, antonyms and translations (and more related kind of terms in the German version).
- It is also interesting to see how different local cultures seem to use different templates
- Wiktionary also integrates well with other Wikimedia sister projects like Wikipedia or Wikiversity. This meets our requirements for a translator's glossary, i.e. our wish to to have access to glossary from both the software strings translation interface and the manual pages.
- We also find it interesting a fairly large amount of users seem to able to cope with the difficult markup language. In Jan 2010, there were over thousand active users in the English version. Most only made a single edit though.
Remark on the history: Most Wikitionary entries, as you can read in the Wiktionary entry of Wikipedia were initially created by bots: “most of the entries and many of the definitions at the project's largest language editions were created by bots that found creative ways to generate entries or (rarely) automatically imported thousands of entries from previously published dictionaries. Seven of the 18 bots registered at the English Wiktionary[4] created 163,000 of the entries there.[5] Only 259 entries remain (each containing many definitions) on Wiktionary from the original import by Websterbot from public domain sources; the majority of those imports have been split out to thousands of proper entries manually.”
Translatewiki.net
“Translatewiki.net is a localisation platform for translation communities, language communities, and open source projects. It started out with localisation for MediaWiki. Later support for MediaWiki extensions, FreeCol and other open source projects was added.” (Translate Wiki, retrieved 14:16, 4 February 2010 (UTC)).
Localization of MediaWiki messages is not easy, as a look at the guidelines demonstrates, since there exist various kinds of messages. They may include various kinds of parameters, simple switches (singular/plural, gender) and even some grammatical transformations needed for some languages.
The translators have a usable environment, i.e. they may either work with the online specialized wiki as shown in the following screen capture or export/import gettext files and then work with a local editor (i.e. POedit).
The translation tool is a mediawiki extenion called "Translate" There don't seem to be special search/comparison tools that would allow translators to make sure that they use a coherent terminology. However, the wiki can be searched for any string.
This software illustrates what a standard translation editor like POedit can do.
The Google translator toolkit
According to the Google translator toolkit basics page, the kit can do the following:
- Upload Word documents, OpenOffice, RTF, HTML, text, Wikipedia articles and knols.
- Use previous human translations and machine translation to 'pretranslate' your uploaded documents.
- Use our simple WYSIWYG editor to improve the pretranslation.
- Invite others (by email) to edit or view your translations.
- Edit documents online with whomever you choose.
- Download documents to your desktop in their native formats --- Word, OpenOffice, RTF or HTML.
- Publish your Wikipedia and knol translations back to Wikipedia or Knol.
When uploading you can/must:(as of 1/2010)
- choose among the four supported formats
- Use translation memory (global or local)
- Use glossary (none, one of yours)
Once a text is uploaded, it stays in Google memory (at least for a while) and users can then do a side by side translation in the supported formats.
- To use the kit with your own Mediawiki
- download the MediaWiki text as UTF-8 and give it a .mediawiki extension
- translate in Translator Toolkit
- download the translation
- post the translation back into your site
- Glossaries
Let's look at Google's Translation memories, glossaries, and placeholders. Part of this kit includes the possibility to upload glossaries and to save TMX files. A glossary is a CSV table with the following format: A arbitrary number of columns with locales (at least) one followed by an optional part of speech (pos) and description columns.
| en-AU | fr | gsw | locale4 | .... | pos | description |
|---|---|---|---|---|---|---|
| lams | mouton | lämmli | noun | Either a software system or variant of sheep. Do not use as a verb | ||
| gate | verrou | schperri | noun | An element in pedagogical sequencing that will filter access to the next element in various ways. (... more needed here ...) |
Since CSV uses commas to separate items, Commas in a cell must be escaped by double-quotes ("). For example, to add the term hello, world!, use "hello, world!". Quotes within quotes are escaped by \. For example, She said, "hello." should be entered as "She said, \"hello.\"". Such glossaries can be made with a spreadsheet (e.g. the google docs) and then be exported as CSV and then imported to the translation tool.
- Translation memory
“A translation memory (TM) is a database of human translations. As you translate new sentences, we automatically search all available translation memories for previous translations similar to your new sentence. If such sentences exist, we rank and then show them to you. Comparing your translation to previous human translations improves consistency and saves you time: you can reuse previous translations or adjust them to create new, more contextually appropriate translations. When you finish translating documents in Google Translator Toolkit, we save your translations to a translation memory so you or other translators can avoid duplicating work.” (Using translation memories, retrieved 15:51, 27 January 2010 (UTC)).
This tool offers features that commercial stand-alone editors have, in particular support for various formats, translation memory and glossary.
Mozilla Projects / Firefox
Let's examine a few features of the Mozilla L10N strategy.
In the Mozilla project, localization strings are managed through XUL. The following fragment defines two strings to be displayed as so-called tokens
<caption label="&<b class="token">identityTitle.label</b>;"/>
<description>&<b class="token">identityDesc.label</b>;</description>
identityTitle.label and identityDesc.label will be substituted by a strings defined in a DTD as entities.
<!ENTITY <b class="token">identityTitle.label</b> "Identity">
<!ENTITY <b class="token">identityDesc.label</b> "Each account has an identity, which is the ↵
↳ information that other people see when they read your messages.">
("↵ ↳" indicates a single line, broken for readability) If you want to find more example constants defined as XML entities, locate the firefox installation directory on your computer and examine chrome/ab-CD.jar file, e.g. en-US.jar.
The L10N tools include
- Use of a text editor that can handle UTF-8 files
- A langpack2cvstree.sh script that converts the en-US language package into another locale.
- A command line/web tool, called compare locales: finds missing and obsolate strings in a localization
- Example: short text that describes the tool
- MozillaBuild: An easy way to install everything you need to checkout/pull and checkin/push your localization and run compare-locales on Windows.
- Mozilla Translator is a tool to help translate programs
- Narro, is a web application that allows online translation and coordination. You can see in operation at l10n.mozilla.org
- Translate Toolkit (moz2po and po2moz): converts various sorts of Mozilla files to Gettext PO format for translation efforts using a PO editor and the other way round. It's used be Pootle for example (see below).
- MozLCDB similiar to PO but more dedicated to Mozilla products
- Pootle a web server for localisation that allows web-based contributions and management. Combined with the Translate Toolkit it allows Mozilla products to be localised online.
- Virtaal is an off-line PO editor developed by the Pootle team.
We wonder a bit who uses which tools. If we understand the situation right, there are several ways to translate as long as the translation does find its way back into the CVS at some point.
Also, it is not suprising, that the project makes a clear distinction between "official releases" and others. Official releases include translation of the installation and migration process, localizing the start page and other web pages built into the product, customizing settings like "live bookmarks", locally relevant search engine plugins, and more.
We had a look at this project in order to catalogue what kind of tools are used in a larger project that must accomodate a large set of users and that tries to make effort to develop online tools (including one for coordination).
LAMS
LAMS is a system for authoring and delivering learning activities, i.e. a learning design and learning activity management software.
This open source project developed an original online solution to support translation. Software translators use three tools:
- An internationalization site (see below) that is augmented with an interface to Google translate
- A LAMS Translators server (that is upgraded after a translation effort so that a translator can check the look and feel on a live system and make sure that there are no conceptual errors)
- A multi-language partitionned wiki for the software documentation. As of June 2010, little documentation has been translation to target languages (except Spanish).
- Editing translation strings
Strings to translate are called labels. A string may include slots to filled in with data and use the syntax {0}, {1}, etc.
To an anonymous user, the LAMS Internationalization site presents a list of available software modules and within each module, completion is shown as the following picture shows.
Translators will see a slighly different cockpit as shown in the following screen shot:
Translators then can display a module, each label is displayed as a list of
- English String, a translation in the target language, update date, translator
The translator then can choose between:
- editing an isolated label
- bulk translate all labels (date and author information of all tags will be overwritten)
- translate only missing labels
To help translation, a provisional translation can be made through Google and to help contextualizing the message, the documentation string used by the software engineers is also displayed ([i]).
Below are a two screen shots that illustrate the principle:
- Homogenization
For the moment, there is no support for language-specific glossary and terminology management.
Good translators may develop several strategies to make sure that a common terminology is used.
Terminology must be homogeneous, e.g. the English word "Cancel" should normally translate to the same french word, e.g. "annuller" (v.s. "abandonner"). One also could argue that translators sometimes have to use less meaningful words, because at some point MS made certain decisions and people are used to it.
"Non-natural" terminology like "branching" or "gates" raise additional challenges. In french I translated this to "verrou" after looking at the German "Sperre". For various reasons I don't like the obvious translation of "Gate" to "Portail" (meaning "Portal"). Verrou means "lock" but also could mean a barrier in some geological sense. Anyhow, if several translators participate or if one translator translates once in a while, there is a very high chance that very different words are being used to deal with the same object. Also in my case, only once I decided to use LAMS for real, I stumbled upon terminology (created by myself) and that I really found unclear.
Fortunately in LAMS (and this is a mission-critical feature), translators can search for labels in any language (Note: Not true actually only in English and the target language) and then see the result in a similar fashion as in the bulk translate window.
This feature allows to see (1) where certain words of the target language are being use (e.g. check if the same word is used for different things, which may or may not be a proble) and (2) more importantly, how a given english word or phrase has been translated.
Since the result displayed is an editable bulk translation window, re-translation is pretty fast.
- Testing
Testing is basically done by playing with a translator's test server. Translators have full rights, e.g. can explore the admin interface, create new teacher and student users and play with these. When the project manager sees that new important translations have been comitted he will update the test server, in particular the weeks before a software upgrade.
- Manual and LAMS web site
As of Jan 2010, manual pages are not translated, but this project is under preparation.
- Under the hood
(additions needed)
- Software strings are Java properties and may include slots for placeholders, e.g.
audit.user.password.change =mot de passe chang\u00e9 pour: {0}
audit.user.password.change =Password changed for: {0}
audit.show.entry =Montrer lentr\u00e9e de lutilisateur {0}. Lentr\u00e9e \u00e9tait {1}
The LAMS translation interface then can extract these strings plus a documentation string inserted by programmers and display all three to the translator.
Formats
In this section we shall have a look at some more popular formats used in Localization.
Lowlevel formats
There exist various methods to handle language strings in computer programs.
Most often, some sort of constants are being used in the code. These constants are then defined either in so-called languages files or in a database.
Let's have a look at an example now. In a mediawiki (the software used for this wiki), default translations of language strings sit in files that are imported to a database when the software is first installed. The format of these constants may be quite different. In the Wikipedia project, constants are defined as keys in associated arrays. The most important one is $messages and includes 2000-3000 strings.
$messages = array(
...
'pagecategories' => '{{PLURAL:$1|Category|Categories}}'
'about' => 'About',
...
);
These strings can be very short, e.g. the 'about' key (constant) tranlates to 'About'. However one also finds messages that extend to half a screen, and that look like this (only a portion is shown):
$messages = array(
.....
'blockedtext' => "<big>'''Your user name or IP address has been blocked.'''</big>
The block was made by $1.
The reason given is ''$2''.
* Start of block: $8
* Expiry of block: $6
* Intended blockee: $7
You can contact $1 or another [[{{MediaWiki:Grouppage-sysop}}|administrator]] to discuss the block.
You cannot use the 'e-mail this user' feature unless a valid e-mail address is specified
in your [[Special:Preferences|account preferences]] and you have not been blocked from using it.
..... (contents removed)
Your current IP address is $3, and the block ID is #$5.
Please include all above details in any queries you make.',
.....
)
Customizing the of mediawiki messages can be done easily by editing the interface strings directly from the wiki. People can find the message they want to change/translate in the Special:Allmessages page and then edit the relevant string in the MediaWiki: namespace. Once edited, these changes are live and will remain even after an upgrade. A side effect of this fairly easy to use system is that willing translators just customize their own wiki, and language files shipped with the mediawiki software are no longer quite up-to-date.
Let's now look at standardized solutions for easing translation of software strings. Language files can be generated from more highlevel formats, such as Gettext or XLIFF. Also Gettext and XLIFF can be generated from computer code and merged back into it. In other words, an alternative solution to creating web-based interfaces as in the Mediawiki and the LAMS project, is to extract Gettext or XLIFF files, put them into a web interface or ship them to translators, and then merge them back.
However the fact that translators have to pay attention to various sorts of placeholders remains a difficulty in all cases.
Gettext
Gettext is a translation strings strategy and technology, popular in open source. is based on the idea that keys used to retrieve local language strings corresponds to the original string used in the source code. Documentation also is added as programming comment just before the corresponing line. From the source code so-called .PO files that are then use by translators.
XLIFF
- XLIFF (XML Localization Interchange File Format) is an XML-based format created to standardize localization. I.e. XLIFF is an alternative to Gettext. XLIFF was standardized by OASIS in 2002. According to the Specification 1.2, XLIFF is the XML Localization Interchange File Format designed by a group of software providers, localization service providers, and localization tools providers. It is intended to give any software provider a single interchange file format that can be understood by any localization provider. It is loosely based on the OpenTag version 1.2 specification and borrows from the TMX 1.2 specification. However, it is different enough from either one to be its own format.
<xliff version='1.2'
xmlns='urn:oasis:names:tc:xliff:document:1.2'>
<file original='hello.txt' source-language='en' target-language='fr'
datatype='plaintext'>
<body>
<trans-unit id='hi'>
<source>Hello world </source>
<target>Bonjour le monde</target>
<alt-trans>
<target xml:lang='es'>Hola mundo</target>
</alt-trans>
</trans-unit>
</body>
</file>
</xliff>
The most important elements are <trans-unit> and <bin-unit>. They contain the translatable portions of the document. The <trans-unit> element contains the text to be translated, the translations, and other related information. The <bin-unit> contains binary data that may or may not need to be translated; it also can contain translated versions of the binary object as well as other related information.
In the trans-unit element, text to be translated is contained in a <source> element, the translated tell will be within the <target> element.
There exist convertors from PO to XLIFF and the other way round.
Translation Memory eXchange
Translation Memory eXchange (TMX) is according to Wikipedia, “an open XML standard for the exchange of translation memory data created by computer-aided translation and localization tools. TMX is developed and maintained by OSCAR[1] (Open Standards for Container/Content Allowing Re-use), a special interest group of LISA[2] (Localization Industry Standards Association). Being in existence since 1998, the format allows easier exchange of translation memory between tools and/or translators with little or no loss of critical data[3]. The current version is 1.4b - it allows for the recreation of the original source and target documents from the TMX data. TMX 2.0 was released for public comment in March, 2007”, retrieved 14:43, 3 February 2010 (UTC).
A TMX files can be very complex (and unlike some other formats like HTML) are not really human readable. E.g. a the sample document found in the specification looks like this:
<?xml version="1.0"?>
<!-- Example of TMX document -->
<tmx version="1.4">
<header
creationtool="XYZTool"
creationtoolversion="1.01-023"
datatype="PlainText"
segtype="sentence"
adminlang="en-us"
srclang="EN"
o-tmf="ABCTransMem"
creationdate="20020101T163812Z"
creationid="ThomasJ"
changedate="20020413T023401Z"
changeid="Amity"
o-encoding="iso-8859-1" >
<note>This is a note at document level.</note>
<prop type="RTFPreamble">{\rtf1\ansi\tag etc...{\fonttbl}</prop>
<ude name="MacRoman" base="Macintosh">
<map unicode="#xF8FF" code="#xF0" ent="Apple_logo" subst="[Apple]"/>
</ude>
</header>
<body>
<tu
tuid="0001"
datatype="Text"
usagecount="2"
lastusagedate="19970314T023401Z" >
<note>Text of a note at the TU level.</note>
<prop type="x-Domain">Computing</prop>
<prop type="x-Project">Pægasus</prop>
<tuv
xml:lang="EN"
creationdate="19970212T153400Z"
creationid="BobW" >
<seg>data (with a non-standard character: ).</seg>
</tuv>
<tuv
xml:lang="FR-CA"
creationdate="19970309T021145Z"
creationid="BobW"
changedate="19970314T023401Z"
changeid="ManonD" >
<prop type="Origin">MT</prop>
<seg>données (avec un caractère non standard: ).</seg>
</tuv>
</tu>
<tu
tuid="0002"
srclang="*all*" >
<prop type="Domain">Cooking</prop>
<tuv xml:lang="EN">
<seg>menu</seg>
</tuv>
<tuv xml:lang="FR-CA">
<seg>menu</seg>
</tuv>
<tuv xml:lang="FR-FR">
<seg>menu</seg>
</tuv>
</tu>
</body>
</tmx>
The OAXAL framework
- Open Architecture for XML Authoring and Localization (OAXAL) is a reference model defining the component parts of XML publishing with respect to the authoring and Localization aspects of the process. It has three main goals:
- Consistency in the authored source-language text
- Consistency in the translated text
- Substantial automation of the Localization process
This references model, according to the Reference Model for Open Architecture for XML Authoring and Localization 1.0, retrieved 18:07, 29 January 2010 (UTC) has two prime use cases:
- Support authoring and localization within a CMS environment
- Support consistency within a translation-only environment
To achieve these goals and handle the use cases OAXAL defined the following software stack:

Let's shortly describe some of these elements:
- ITS (Internationalization Tag Set (ITS) Version 1.0) “is a technology to easily create XML which is internationalized and can be localized effectively. On the one hand, the ITS specification identifies concepts (such as "directionality") which are important for internationalization and localization. On the other hand, the ITS specification defines implementations of these concepts (termed "ITS data categories") as a set of elements and attributes called the Internationalization Tag Set (ITS).”. This work is explained in a Best Practices for XML Internationalization working group note.
Basically ITS allows you to insert tags into an XML tree that will tell systems (and human readers) of XML what should not be translated....
Below we reproduce a simple ITS example:
<dbk:article
xmlns:its="http://www.w3.org/2005/11/its"
xmlns:dbk="http://docbook.org/ns/docbook"
its:version="1.0" version="5.0" xml:lang="en">
<dbk:info>
<dbk:title>An example article</dbk:title>
<dbk:author
its:translate="no">
<dbk:personname>
<dbk:firstname>John</dbk:firstname>
<dbk:surname>Doe</dbk:surname>
</dbk:personname>
<dbk:affiliation>
<dbk:address>
<dbk:email>foo@example.com</dbk:email>
</dbk:address>
</dbk:affiliation>
</dbk:author>
</dbk:info>
<dbk:para>This is a short article.</dbk:para>
</dbk:article>
OAXAL defines (fairly complicated) workflows for document life cycles. From a high-level perspective, the life-cycle for localization-only workflows (e.g. as in sofware localization) looks like this:
The key step is to extract some XLIFF file with translation string that then will be used to translate and merged back.
- Translation Memory eXchange (TMX) “is an open XML standard for the exchange of translation memory data created by computer-aided translation and localization tools. TMX is developed and maintained by OSCAR (Open Standards for Container/Content Allowing Re-use), a special interest group of LISA (Localization Industry Standards Association” (Wikipedia, retr. jan 2010).
Software
This section should include a short list of useful software. There exist other (better) indexes, e.g. the Compendium of Translation Software, a directory of commercial machine translation systems and computer-aided translation support tools, compiled by John Hutchins.
For other online tools, such as glossaries, see the links section below.
- PO editors
See gettext for more
- Web-based systems (to install locally)
- Extension:Translate is a Mediawiki extensions, e.g. could be installed in this wiki.
- Free translation tools
- ForeignDesk (idle project since 2002)
- Free online translation support systems
- Google translate. Note: There is a way to get support for mediawiki files. Upload a filed called *.mediawiki. E.g. edit wikipage and copy/paste source or get it by &action=raw URL Get parameter, etc. Do not whine if some formatting doesn't render well (each mediawiki is different). This is a non-documented feature and we guess that it may become official after some further development - Daniel K. Schneider 18:07, 29 January 2010 (UTC).
- Frameworks
- The Okapi Framework is a set of interface specifications, format definitions, components and applications that provides an environment to build interoperable tools for the different steps of the translation and localization process. (Seems to be a live project).
- Okapi filters
- Components
- downloads (include a localization toolbox and a translation memory editor).
- Links of links
- Quality / Evaluation
- Quality Model Builder - zipped file. (QMB) allows software designers and end-users to develop a hierarchical quality model to help in the evaluation of complex software.
- ROTE - zipped file (ROTE) - is designed to help end-users rank the relative importance of their user requirements in order to guide software developers as to the priorities that should be attached to individual requirements.
Open source localization guidelines
The idea behind writing this wiki article was to come up with some suggestions/guidelines concerning localization in volunteer-based substantial open source projects.
(under construction - 21:04, 28 January 2010 (UTC) !)
Here is what we have got so far (very provisional)
Integrate usability issues into the translation process
Open source projects can profit from the fact that translators will use the software themselves. Therefore, they will stumble on surface usability and cognitive ergonomics issues. I.e. stuff that is hard to translate may be problematic in the source language to start with.
To support reflection about these issues, it may be a good idea to create a combined translation + ergonomics forum. An other idea would be to add a discussion field to each translated item where people could add suggestions and complaints. In the same spirit, one should consider implementing end-user commenting system that could be enabled by system administrators (see below).
This is related to the next point (common grounding)
Ensure common grounding of essential terms
Early in the project, start a collaborative glossary/terminology project, i.e. some kind of "controlled vocabulary" project. This glossary should include all major terms used in the UI or the manuals. Such a project should have the following features for a term that has a single meaning (for polysemic objects, this list must be duplicated):
- Entry term
- Definition: a short definition
- Synonyms (equivalent terms) (but that should not be used in neither the UI nor the manuals)
- Contexts (e.g. for an LMS: types of pedagogical scenarios, pedagogical schools of thought)
- Sources, e.g. links to articles on stable websites and/or publications (DOI's)
- Links to other languages (one may have to allow for more than one link/language)
- Comments (i.e. other translators and users could tell if they agree with the above)
Provide a translator's toolbox for software strings
The toolbox should focus on four things:
- Ensure consistency (i.e. use the same words for the same UI element, use terms that "fit" together, and finally respect the spirit of the source language if possible)
- Ensure meaninfulness (in particular, translation of UI strings happen out of context, which is a problem that must be addressed)
- Boost efficiency
- Favor collaboration (translators ought to be able to argue with each other)
An online translation system should have the following features:
- Be able to concurrently display source + and target language (maybe two for comparison).
- Search all terms in target or source language and then display all the terms again in triplets as above.
- Display information strings and (if existing) constant/parameter names used by coders).
- Ideally, there should be a way to see the real context, e.g. a screen capture.
- Be able to annotate each term with comments (but see next item), i.e. a small icon next to each translation string for entering a new comment or indicating that there are comments.
- A semi-automatic link to the glossary where comments also could be made.
- Translated items should be clearly attributed to a single translator, including revisions if possible.
- Support some form of translation memory, i.e. the system should provide a default translation of a string if possible.
- Each translated item must be attributed to an author in order to insure tracability (who did what and who believes what). This is an technical issue when translators can make global edits (either via long online forms or by checking out/in a translation file).
- Manuals should use wiki technology and for various reasons: Collaborative editing, hyperlinks, history, etc.
Come up with incentives
There should be some kind of incentives for the translators. One also might try to suggest to local communities to find monetary incentives provided by localized communities (this is about OSS without resources to pay translators). E.g. a German fund might pay money to German translators and a French fund might pay a trip to Australia.
Research partnerships with translation or localization research groups should be considered. For example, translation researchers could study translators' behavior in collaborative on-line environments in exchange for productive help with translation for example. Software developers of new translation tools might cooperate with a live project. Localization and computer assisted translation is an academic (and commercial) growth market and these folks need the possibility for ecologically valid field research.
Have end-users participate
"Normal" end user's should be given the opportunity to participate. Windows, Google and Wiktionary do it, so can we. I.e. there should button in the Interface that a user can hit for feedback. Feedback should be very simple, e.g. with radio buttons (but include the possibility to add a message.)
- This is not clear (why)
- This has a typo (what);
- There is a better term (which/why)
- This uses a different language (with respect to what)
- etc.
The big question is where to position such a button and how it could detect what the user was talking about ...
Plan globally for all product items
If these are planned early, there should be some efficiency and quality gains. In particular translation memory if implemented somewhat and an integrated glossary could both improve quality and lower translation cost.
Main genres to think about:
- Software localization in the narrow sense (UI and system messages)
- In-software help (if existing)
- Glossary (to be used by all actors, i.e. translators, developers, all category of software users, e.g. in e-learning authors, teachers, students)
- Manuals of all sorts.
Train the volunteer translators
Volunteer translators need a little bit of training, but it should be as light-weight as possible:
- Make sure that they think about some fundamental rules like consistency of the vocabulary, a vocabulary that "fits together", and the need for testing (with end-users if possible)
- Make sure that they understand what translation tools they may use and what kind of functionalities each one has
- Provide easy to find pointers to online dictionaries (e.g. the Microsoft language portal :)
In addition, one should try to make them active partners with respect to other issues like ergonomics as we argued above.
Links
Texts and web sites about software localization
- Definitions
- Organizations
- Localization Industry Standard Association (LISA)
- The Globalization Insider (LISA News)
- Globalization and Localization Association (GALA)
- Technology Development for Indian Languages (TDIL)
- W3CInternationalization (I18n) Activity - Internationalization Tag Set Interest Group Home Page
- Localisation Resource Center (LRC) (A information, educational, and research centre for the localisation community. University College Dublin).
- Software Localisation Interest Group (SLIG)
- How-to / tutorials
- Articles, best practices & tutorials. A list provided by the W3C Internationalization (I18n) Activity: Making the World Wide Web truly world wide!
- Localisation Guide and Document translation at Sourceforge.
- How to Localize Software (Developer-resource.com, retrieved 16:27, 21 January 2010 (UTC)).
- Software Localization versus Translation, TranslatorsCafé.com, by Alexander Schunk. Submitted on March 22, 2008
- for Developing Non-English Web Sites by [http://tlt.psu.edu/ Teaching and Learning with Technology, Penn State University (includes several good web pages, e.g. about HTML "lang" attribute.
- Seven Habits, advice from LISA.
- The Pavel Terminology Tutorial. This is substantial tutorial on all aspects regarding terminology made by the Canadian Translation bureau (make sure to explore all the menus, there are dozens of pages ...)
- Der Softwarelokalisierungsprozess, Praktische Fingerübungen in 10 Sätzen, by Joseph Dengler. (but focus on a specific product)
- Translator identities: multiple personalities or a dynamic whole?, blog post by Sarah Dillon.
- Localization Guide: Getting Started in Localization by Dan Johnson et al. (includes several articles)
- XLIFF
- XML in localisation: Use XLIFF to translate documents by Rodolfo M. Rava.
- XLIFF: An Aid To Localization, retrieved 18:07, 29 January 2010 (UTC). (Oracle/Sun Developer Network (SDN).
- About language file formats
- XLIFF: An Aid To Localization by John Corrigan and Tim Foster, Sun Developer Network.
- XLIFF (Wikipedia)
Glossaries and other structured data
- Internationalization
- Dotnet-culture.net provides information about date/time and decimal/currency representation.
- Terminology databases
- Le grand dictionnaire terminologique (english/french)
- The Open Terminology Forum french, english, spanish, chinese (?). Limited to some subdomains / maintained by volonteers. This website might be of interest to some open source localization projects, either for hosting a project or to get some inspiration.
- Termium Plus (The Government of Canada's terminology and linguistic data bank).
- wiktionary.org (The free dictionary, a sister project of wikipedia). Includes translations.
- Microsoft Terminology Translations. The Microsoft language portal includes both a terminology database (terms and translations) and all translations of all localized MS products. Also available as CSV format download.
Other
- Example Projects and languages
- Mozilla
- Does Internalization through the XUL User Interface Language
- L10n:Home Page
- Mozilla Localization Project (Archives)
- Courses
- Software Localization MCLS 600012 taught by Gregory M. Shreve. (2001, retrieved 16:27, 21 January 2010 (UTC)). Includes PPT and HTML files for reading. Also available here
- Lecture 1
- What is Software Localization? A list Alexa Dubreuil that summarizes the course syllaus
Software links
- Translate Toolkit (Wikipedia)
- Sun Open Language Tools (XLIFF system)
- More: Trados® Freelance™, Atril Déjà Vu, STAR Transit, SDLX™, IBM TranslationManager,
- Indexes
- Translators’ On-Line Resources, hosted by the Translation Journal.
- Free and Open Source Software for Translators, an index page made by Corinne McKay (Translator)
Bibliography
- Dohler, Per N. (1979). Facets of Software Localization, A Translator's View. Translation Journal 1, July 1997. (retrieved 16:27, 21 January 2010 (UTC))
- McKethan, Kenneth A. (Sandy)Jr. and Graciela White (2005). Demystifying Software Globalization, Translation Journal 9 (2), April 2005. HTML, retrieved 16:27, 21 January 2010 (UTC).
- Esselink Bert (2000a), A Practical Guide to Localization, , John Benjamins Publishing, ISBN 1-58811-006-0
- Esselink Bert (2000b) The Evolution of Localization. Amsterdam, Philadelphia: John Benjamins Publishing Company, 2000
- Karunakar, G. and Shirvastava, R. (2007) Evolving Translations & Terminology - The Open Way, LRIL-2007 - National Seminar on Creation of Lexical Resources for Indian Language Computing and Processing at C-DAC Mumbai. PDF
- Muegge, Uwe (2007). "Disciplining words: What you always wanted to know about terminology management". tcworld (tekom) (3): 17–19. PDF
- Wittner Janaina & Daniel Goldschmidt (2007), Technical Challenges and Localization Tools, Localization Getting Started, Multilingual, October/November 2007 Supplemental Guide. (PDF, retrieved 20:59, 10 February 2010 (UTC).)