The educational technology and digital learning wiki
Jump to navigation
Jump to search
|
|
| Line 32: |
Line 32: |
| |field_last_edition=2014/03/24 | | |field_last_edition=2014/03/24 |
| }} | | }} |
| [[File:UimaFramework.png|left|200px]]The Frameworks run the components, and are available for both Java and C++. The Java Framework supports running both Java and non-Java components (using the C++ framework). The C++ framework, besides supporting annotators written in C/C++, also supports Perl, Python, and TCL annotators. The UIMA-AS and UIMA-DUCC are both Scaleout Frameworks and are addons to the base Java framework. The UIMA-AS supports very flexible scaleout capability based on JMS (Java Messaging Services) and ActiveMQ. The UIMA-DUCC extends UIMA-AS by providing cluster management services to automate the scale-out of UIMA pipelines over computing clusters. | | [[File:UimaFramework.png|left|500px]]The Frameworks run the components, and are available for both Java and C++. The Java Framework supports running both Java and non-Java components (using the C++ framework). The C++ framework, besides supporting annotators written in C/C++, also supports Perl, Python, and TCL annotators. The UIMA-AS and UIMA-DUCC are both Scaleout Frameworks and are addons to the base Java framework. The UIMA-AS supports very flexible scaleout capability based on JMS (Java Messaging Services) and ActiveMQ. The UIMA-DUCC extends UIMA-AS by providing cluster management services to automate the scale-out of UIMA pipelines over computing clusters. |
|
| |
|
| The frameworks support configuring and running pipelines of Annotator components. These components do the actual work of analyzing the unstructured information. Users can write their own annotators, or configure and use pre-existing annotators. Some annotators are available as part of this project; others are contained in various repositories on the internet. | | The frameworks support configuring and running pipelines of Annotator components. These components do the actual work of analyzing the unstructured information. Users can write their own annotators, or configure and use pre-existing annotators. Some annotators are available as part of this project; others are contained in various repositories on the internet. |
|
| |
|
| Additional infrastructure support components include a simple server that can receive REST requests and return annotation results, for use by other web services. | | Additional infrastructure support components include a simple server that can receive REST requests and return annotation results, for use by other web services. |
Revision as of 11:31, 24 March 2014
Unstructured Information Management Applications 2.5.0 (2014/01/14)
Developed by: IBM (originally) Apache software foundation (now)
License: Apache License
Web page : Tool homepage
Tool type : Framework/Library/API, {{{field_language}}}
The last edition of this page was on: 2014/03/24
The Completion level of this page is : Low
The last edition of this page was on: 2014/03/24 The Completion level of this page is : Low
SHORT DESCRIPTION
Unstructured Information Management Architecture (UIMA) is a component framework to analyze unstructured content such as text, audio and video. This is originally developed by IBM.
UIMA enables applications to be decomposed into components, for example “language identification” => “language specific segmentation” => “sentence boundary detection” => Each component implements interfaces defined by the framework and provides self describing metadata via XML descriptor files. Also provides capabilities to wrap components as network services, and can scale to very large volumes by replicating processing pipelines over a cluster of networked nodes.
TOOL CHARACTERISTICS
Usability
Authors of this page consider that this tool is difficult to use.
Tool orientation
This tool is designed for general purpose analysis.
Data mining type
This tool is made for Text mining, Image mining, Audio mining, Video mining.
Manipulation type
This tool is designed for Data extraction, Data transformation.
| Tool objective(s) in the field of Learning Sciences |
|
☑ Analysis & Visualisation of data
☑ Predicting student performance
☑ Student modelling
☑ Social Network Analysis (SNA)
☑ Constructing courseware
|
☑ Providing feedback for supporting instructors:
☑ Recommendations for students
☑ Grouping students:
☑ Developing concept maps:
☑ Planning/scheduling/monitoring
☑ Experimentation/observation
|
ABOUT USERS
Tool is suitable for:
Students/Learners/Consumers
Teachers/Tutors/Managers
Researchers
Developers/Designers
Organisations/Institutions/Firms
Others
Required skills:
SYSTEM ADMINISTRATION: Advanced
DATA MINING MODELS: Medium
FREE TEXT
Tool version : Unstructured Information Management Applications 2.5.0 2014/01/14
(blank line)
Developed by : IBM (originally) Apache software foundation (now)
(blank line)
Tool Web page : http://uima.apache.org/
(blank line)
Tool type : Framework/Library/API
(blank line)
License:Apache License
| 
|
SHORT DESCRIPTION
Unstructured Information Management Architecture (UIMA) is a component framework to analyze unstructured content such as text, audio and video. This is originally developed by IBM.
UIMA enables applications to be decomposed into components, for example “language identification” => “language specific segmentation” => “sentence boundary detection” => Each component implements interfaces defined by the framework and provides self describing metadata via XML descriptor files. Also provides capabilities to wrap components as network services, and can scale to very large volumes by replicating processing pipelines over a cluster of networked nodes.
TOOL CHARACTERISTICS
| Tool orientation |
Data mining type |
Usability |
| This tool is designed for general purpose analysis. |
This tool is designed for Text mining, Image mining, Audio mining, Video mining. |
Authors of this page consider that this tool is difficult to use. |
| Data import format |
Data export format |
| . |
. |
| Tool objective(s) in the field of Learning Sciences |
|
☑ Analysis & Visualisation of data
☑ Predicting student performance
☑ Student modelling
☑ Social Network Analysis (SNA)
☑ Constructing courseware
|
☑ Providing feedback for supporting instructors:
☑ Recommendations for students
☑ Grouping students:
☑ Developing concept maps:
☑ Planning/scheduling/monitoring
☑ Experimentation/observation
|
Can perform data extraction of type:
Can perform data transformation of type:
Simple data transformation operations, Advanced data transformation operations
Can perform data analysis of type:
Can perform data visualisation of type:
(These visualisations can be interactive and updated in "real time")
ABOUT USER
| Tool is suitable for: |
| Students/Learners/Consumers:☑ |
Teachers/Tutors/Managers:☑ |
Researchers:☑ |
Organisations/Institutions/Firms:☑ |
Others:☑ |
| Required skills: |
| Statistics: BASIC |
Programming: ADVANCED |
System administration: ADVANCED |
Data mining models: MEDIUM |
OTHER TOOL INFORMATION
|
| UIMA.png
|
| UIMA logo.png
|
| Unstructured Information Management Applications
|
| Apache License
|
| Free&Open source
|
| IBM (originally) Apache software foundation (now)
|
| 2014/01/14
|
| 2.5.0
|
| http://uima.apache.org/
|
| Unstructured Information Management Architecture (UIMA) is a component framework to analyze unstructured content such as text, audio and video. This is originally developed by IBM.
UIMA enables applications to be decomposed into components, for example “language identification” => “language specific segmentation” => “sentence boundary detection” => Each component implements interfaces defined by the framework and provides self describing metadata via XML descriptor files. Also provides capabilities to wrap components as network services, and can scale to very large volumes by replicating processing pipelines over a cluster of networked nodes.
|
| General analysis
|
|
|
| Developers/Designers
|
| Basic
|
| Advanced
|
| Advanced
|
| Medium
|
| Framework/Library/API
|
|
|
|
|
| Text mining, Image mining, Audio mining, Video mining
|
| Data extraction, Data transformation
|
|
|
| Simple data transformation operations, Advanced data transformation operations
|
|
|
|
|
|
|
|
|
|
|
|
|
| difficult to use
|
|
|
| Low
|
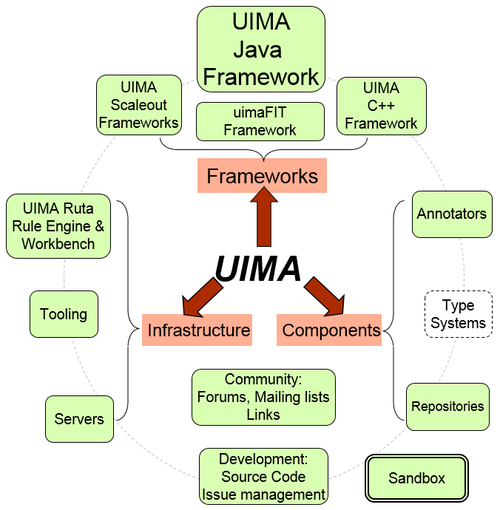
The Frameworks run the components, and are available for both Java and C++. The Java Framework supports running both Java and non-Java components (using the C++ framework). The C++ framework, besides supporting annotators written in C/C++, also supports Perl, Python, and TCL annotators. The UIMA-AS and UIMA-DUCC are both Scaleout Frameworks and are addons to the base Java framework. The UIMA-AS supports very flexible scaleout capability based on JMS (Java Messaging Services) and ActiveMQ. The UIMA-DUCC extends UIMA-AS by providing cluster management services to automate the scale-out of UIMA pipelines over computing clusters.
The frameworks support configuring and running pipelines of Annotator components. These components do the actual work of analyzing the unstructured information. Users can write their own annotators, or configure and use pre-existing annotators. Some annotators are available as part of this project; others are contained in various repositories on the internet.
Additional infrastructure support components include a simple server that can receive REST requests and return annotation results, for use by other web services.



{kind=link}
{kind=link}