« RapidMiner Studio » : différence entre les versions
mAucun résumé des modifications |
Aucun résumé des modifications |
||
| Ligne 6 : | Ligne 6 : | ||
|difficulté=intermédiaire | |difficulté=intermédiaire | ||
}} | }} | ||
= Introduction = | = Introduction = | ||
RapidMiner est un outil utilisé pour le mining, le traitement de données et le machine learning. Cela permet d’importer des bases de données et les moduler à travers ses nombreuses fonctions pour extraire le type de données souhaité. Par exemple, on peut sélectionner des attributs spécifiques, trouver et filtrer les données “inutiles” et créer ainsi des modèles prédictifs. Le logiciel est compatible avec beaucoup de databases, comme Excel et MySQL, et ses opérations sont décrites en XML en permettant une grande flexibilité. | |||
= Installation = | = Installation = | ||
| Ligne 39 : | Ligne 39 : | ||
* De nombreuses sources de données : Excel, Access, Oracle, IBM DB2, Microsoft SQL, Sybase, Ingres, MySQL, Postgres, SPSS, dBase, Text files, et d'autres encore ... | * De nombreuses sources de données : Excel, Access, Oracle, IBM DB2, Microsoft SQL, Sybase, Ingres, MySQL, Postgres, SPSS, dBase, Text files, et d'autres encore ... | ||
* RapidMiner vous permet de travailler avec différents types et tailles de sources de données | * RapidMiner vous permet de travailler avec différents types et tailles de sources de données | ||
= Type de données = | |||
Avec RapidMiner, il est possible d’importer tout type de données que ce soit des données enregistrées sur des fichiers ou des données hébergées sur des bases de données externes sql et nosql. D’après le site de RapidMiner, il est notamment possible d’intégrer des entiers (integer), des réels (real), des données numériques, du binomial, du polynomial, des données nominales, ainsi que des dates. De cette manière, on peut intégrer des données opérationnelles ou transactionnelles (données de coûts par exemple), des données non opérationnelles (données prévisionnelles par exemple) et des métadonnées (données concernant les données elles-mêmes). | |||
= Nature des traitements possibles = | |||
RapidMiner offre une vaste gamme d'outils pour le traitement de données que ce soit pour le prétraitement ou pour le traitement. Ces outils, ou opérateurs, permettent d’effectuer un grand nombre d’actions qui vont de l'importation et l’exportation des bases de données, au filtrage et la réorganisation des données. Le rayon des possibilités que cet outil offre est tellement vaste qu’il est impossible de les résumer dans cet article, cependant on se limitera à en décrire ceux qui apparaissent être les principaux. Pour ce faire il y a deux concepts clés à retenir, les concepts de data blending et de data cleansing. | |||
Le data blending (littéralement “fusion de données”) est, comme le nom le suggère, l’action de prendre des données de différentes bases de données et de les fondre ensemble. RapidMiner (à la version actuelle) offre 82 opérateurs liés à cette pratique, voici les plus basiques: | |||
*'''Union''': cet opérateur permet de mettre ensemble deux bases de données. Le résultat est une base de données unifiée avec les données de la première plus les données de la deuxième. Si une base de donnée a des attributs qui ne sont pas dans l’autre, certaines données seront manquantes, donc il est préférable de l’utiliser avec des bases de données ayant les mêmes attributs. | |||
*'''Join''': cet opérateur permet de mettre ensemble deux bases de données sur la base d'attributs clés que les deux ont en commun. Par exemple, si on a une base de données avec une liste de produits et une base de données avec les produits vendus et que les deux ont l'attributs commun "ID produit", alors les deux bases de données peuvent être mises ensemble en prenant "ID produit" comme point de référence. Le résultat est une base de données unifiée où les données sont mises en commun en minimisant la possibilité d’avoir des données manquantes comme dans le cas de “union”. | |||
Le data cleansing (nettoyage de données) est une pratique, surtout utilisée en phase de prétraitement, qui permet de se libérer des données “inutiles” comme les données manquantes, des données étranges qui peuvent être causés par des erreurs de measurements, ou bien qui sont triviaux pour le type d’analyse qu’on est en train d’effectuer, RapidMiner offre 28 opérateurs pour le data cleansing, voici certains exemples: | |||
*'''Replace Missing Values''': comme on peut le comprendre depuis le nom, cela permet de remplacer les données manquantes avec des données fictives qui n’ont pas d’influence relevante dans les résultats. | |||
*'''Normalize''': ceci permet d’uniformiser différentes données numériques en les mettant sur la même échelle, cela permet par exemple de trouver plus facilement des valeurs étranges avec l’aide de l’opérateur Detect Outlier (Distances) | |||
Autre que le data blending et le data cleansing, on a aussi d'autres modes de traitement de données: par exemple, on a la possibilité de créer des modèles (en totalité on a à disposition 167 types de modèles). Parmi ceux-là on a des modèles prédictifs (63 au total), dont un est expliqué dans le tutoriel: le '''Decision Tree'''. En plus on a aussi des modèles de segmentation (14), d’associations (6), de corrélations (8), de similarité (4) etc. | |||
Parmi les autres modes de traitement de données, on a aussi la possibilité de créer des '''Macros''' qui sont un concept similaire aux variables dans la programmation et qui permettent d’effectuer des opérations complexes, comme décider combien de données visualiser et selon quel critère. Il est possible aussi de générer des tables en Excel ou autres formats et sauvegarder les bases de données traitées sur son ordinateur et beaucoup d’autres fonctionnalités encore. | |||
Enfin RapidMiner permet de visualiser ces données à travers une vaste gamme de graphiques. | |||
= Visualisations offertes = | |||
En important une base de données, il est directement possible d’observer ces données sous forme de tableau simplement en cliquant sur “results” dans la barre principale et “data” dans la barre latérale. Si l’on prend par exemple, le tutoriel proposé par RapidMiner, il est possible d’obtenir plus d’informations concernant les passagers du Titanic. | |||
En cliquant sur l'onglet “statistics” dans la barre latérale, on obtient des statistiques plus précises sur chaque colonne du tableau de l’onglet “data”. Par exemple, si l’on s’intéresse à l’âge des passagers, on peut voir que la moyenne d’âge est d’environ 30 ans, que la personne la plus jeune avait moins d’un an et que la plus âgée avait 80 ans. | |||
En cliquant sur “open visualizations”, l’onglet “visualizations” dans la barre latérale s’ouvre. On peut choisir plusieurs types de visualisations. Les deux grandes catégories sont les graphiques (“charts”) et les cartes (“maps”). Dans la première, on retrouve 36 types de graphiques différents. Ils permettent de regarder les données de manière différente, en fonction de ce qu’on cherche à mettre en avant. | |||
On peut par exemple utiliser le diagramme circulaire ou la pyramide pour montrer des pourcentages de différentes catégories de la base de données. Si l’on prend l’exemple du tutoriel, on pourrait par exemple voir le pourcentage de passagers ayant survécu ou non, tout comme le pourcentage de femmes ou d’hommes parmi les passagers. Egalement, on peut utiliser un diagramme en boîte. Avec celui-ci, on peut obtenir la valeur minimum et la valeur maximum d’une base de données, mais aussi la médiane et le 1er et 3ème quartile. Si l’on prend l’exemple du Titanic, on peut choisir le type de données à observer (âge par ex.) et si l’on souhaite diviser cette observation en différents groupes. Ainsi, on peut par exemple observer l’âge des passagers du Titanic en fonction de leur sexe: | |||
On remarque alors que la femme la plus agée avait 76 ans, tandis que l’homme le plus âgé avait 80 ans. De plus, on peut voir que 50% des hommes avaient entre 30 et presque 1 an. Les autres 50% avaient entre 30 et 80 ans. | |||
Pour ce qui est de la catégorie des cartes, on retrouve 3 types de cartes différentes. Les utiliser Pour l’exemple issu du tutoriel de RapidMiner, si l’on avait accès aux nationalités des passagers, on aurait notamment pu visualiser sur les cartes, le nombre de passagers par pays. | |||
= Points forts et limites = | |||
RapidMiner est certainement un outil qui offre une vaste gamme de possibilités et qui est flexible. Il possède une interface qui permet de visualiser le processus de traitement de données à travers un système de drag and drop où les opérateurs sont trascinés sur l’écran et mis en lien, cela donne ainsi au logiciel une interface intuitive et plaisante à utiliser. La quantité d’opérateurs à disposition permet aussi d’effectuer des traitements complexes sur les bases de données et d’extraire les informations qu'on nécessite de façon rapide et sans besoin de connaissances de programmation. Il y a également la possibilité de visualiser les données à travers nombreux modèles et graphiques rendant tout l’ensemble intéressant. Le fait d’avoir à disposition une version gratuite de RapidMiner pour l’éducation en permettant d’explorer toutes les fonctionnalités sans limitations, est aussi un point positif. | |||
Cependant, malgré la présence d’un tutoriel qui nous aide à effectuer les premiers pas avec RapidMiner en nous familiarisant à certaines opérations de base, l’outil est très difficile à maîtriser, surtout pour ceux qui s’approchent pour la première fois du domaine de l’analyse et de l’extraction de données, aussi les instructions offertes par le site du logiciel ne sont pas toujour faciles à comprendre. Dans ce cas, la grande disponibilité d’opérations possibles se heurte à un temps d’apprentissage très long et une complexité qui peut effrayer les débutants et cela malgré la possibilité de visualiser les opérations. Un autre limite concerne l’accessibilité au niveau du prix. En effet, si l’on n’a pas droit à la version pour l’éducation qui est gratuite pendant un an et qui est quand-même limitée dans le nombre de données analysables, il faut acheter le produit pour profiter de tout son potentiel. Pour ce qui concerne le prix il y a aussi un manque de transparence, car cela n’est pas directement accessible sur le site web du producteur, mais en regardant les nombreux commentaires sur internet on nous laisse entendre que cela coûte cher. Pour terminer, RapidMiner est un outil qui n’est pas encore développé en français et même si on trouve rares documents en français sur internet, la langue peut être une barrière pour comprendre comment tout fonctionne. | |||
= Examples d'utilisation = | = Examples d'utilisation = | ||
Version du 24 mars 2022 à 21:32
| Analytique et exploration de données | |
|---|---|
| Module: Outils text mining | |
| ⚐ à finaliser | ☸ intermédiaire |
| ⚒ 2022/03/24 | |
| Catégorie: Outils text mining | |
Introduction
RapidMiner est un outil utilisé pour le mining, le traitement de données et le machine learning. Cela permet d’importer des bases de données et les moduler à travers ses nombreuses fonctions pour extraire le type de données souhaité. Par exemple, on peut sélectionner des attributs spécifiques, trouver et filtrer les données “inutiles” et créer ainsi des modèles prédictifs. Le logiciel est compatible avec beaucoup de databases, comme Excel et MySQL, et ses opérations sont décrites en XML en permettant une grande flexibilité.
Installation
- L'installation de RapidMiner Studio est très facile sur Windows (testé avec Windows 7 x64, Windows 8 x64 et Windows 10 technical preview x64), à partir de l'exécutable téléchargé sur la page de votre compte RapidMiner (l'inscription est obligatoire).
- L'installation de RapidMiner Studio sur Mac OS X s'est révélé être compliquée, du fait de ses dépendances en Java. Le système intègre Java 1.8 (OS X 10.10.1) et RapidMiner demande la version 1.7 ne détectant que la version 1.6.
Note : RapidMiner Studio est désormais un logiciel commercial, l'utilisation de celui-ci (et de ses fonctions de base) est désormais limité à 14 jours après avoir fait la demande de license.
Un jeu d'outils complet
Tout d'abord, il me semble important de dire que RapidMiner Studio - et RapidMiner Server qui le complète - est un jeu d'outils complet, plus qu'un logiciel spécifique. Le site web de RapidMiner nous dit que RapidMiner vous laisse parcourir et exécuter avec facilité parmi plus de 1500 opérations.
Dû fait de cette complexité, je n'explorerais et décrirais que certaines des fonctionnalités de RapidMiner Studio. Je m'intéresserais donc tout d'abord au "mining" de texte classique, à partir de documents locaux; j'explorerais ensuite comment il est possible avec cet outil, d'importer, de transformer et d'analyser des tweets (tweets mining).
Les principales forces de RapidMiner selon ses éditeurs sont :
- Un environnement visuel - "code-free" - que l'on peut utiliser sans maitriser de langage de programmation
- Sa disponibilité sur les principaux systèmes d'exploitation et plateformes
- Sa principale fonction est le "design" de processus d'analyses
- Analyses prédictives
- Chargement de données
- Transformation de données
- Modélisation de données
- Visualisation de données
- Extension par API
- De nombreuses sources de données : Excel, Access, Oracle, IBM DB2, Microsoft SQL, Sybase, Ingres, MySQL, Postgres, SPSS, dBase, Text files, et d'autres encore ...
- RapidMiner vous permet de travailler avec différents types et tailles de sources de données
Type de données
Avec RapidMiner, il est possible d’importer tout type de données que ce soit des données enregistrées sur des fichiers ou des données hébergées sur des bases de données externes sql et nosql. D’après le site de RapidMiner, il est notamment possible d’intégrer des entiers (integer), des réels (real), des données numériques, du binomial, du polynomial, des données nominales, ainsi que des dates. De cette manière, on peut intégrer des données opérationnelles ou transactionnelles (données de coûts par exemple), des données non opérationnelles (données prévisionnelles par exemple) et des métadonnées (données concernant les données elles-mêmes).
Nature des traitements possibles
RapidMiner offre une vaste gamme d'outils pour le traitement de données que ce soit pour le prétraitement ou pour le traitement. Ces outils, ou opérateurs, permettent d’effectuer un grand nombre d’actions qui vont de l'importation et l’exportation des bases de données, au filtrage et la réorganisation des données. Le rayon des possibilités que cet outil offre est tellement vaste qu’il est impossible de les résumer dans cet article, cependant on se limitera à en décrire ceux qui apparaissent être les principaux. Pour ce faire il y a deux concepts clés à retenir, les concepts de data blending et de data cleansing.
Le data blending (littéralement “fusion de données”) est, comme le nom le suggère, l’action de prendre des données de différentes bases de données et de les fondre ensemble. RapidMiner (à la version actuelle) offre 82 opérateurs liés à cette pratique, voici les plus basiques:
- Union: cet opérateur permet de mettre ensemble deux bases de données. Le résultat est une base de données unifiée avec les données de la première plus les données de la deuxième. Si une base de donnée a des attributs qui ne sont pas dans l’autre, certaines données seront manquantes, donc il est préférable de l’utiliser avec des bases de données ayant les mêmes attributs.
- Join: cet opérateur permet de mettre ensemble deux bases de données sur la base d'attributs clés que les deux ont en commun. Par exemple, si on a une base de données avec une liste de produits et une base de données avec les produits vendus et que les deux ont l'attributs commun "ID produit", alors les deux bases de données peuvent être mises ensemble en prenant "ID produit" comme point de référence. Le résultat est une base de données unifiée où les données sont mises en commun en minimisant la possibilité d’avoir des données manquantes comme dans le cas de “union”.
Le data cleansing (nettoyage de données) est une pratique, surtout utilisée en phase de prétraitement, qui permet de se libérer des données “inutiles” comme les données manquantes, des données étranges qui peuvent être causés par des erreurs de measurements, ou bien qui sont triviaux pour le type d’analyse qu’on est en train d’effectuer, RapidMiner offre 28 opérateurs pour le data cleansing, voici certains exemples:
- Replace Missing Values: comme on peut le comprendre depuis le nom, cela permet de remplacer les données manquantes avec des données fictives qui n’ont pas d’influence relevante dans les résultats.
- Normalize: ceci permet d’uniformiser différentes données numériques en les mettant sur la même échelle, cela permet par exemple de trouver plus facilement des valeurs étranges avec l’aide de l’opérateur Detect Outlier (Distances)
Autre que le data blending et le data cleansing, on a aussi d'autres modes de traitement de données: par exemple, on a la possibilité de créer des modèles (en totalité on a à disposition 167 types de modèles). Parmi ceux-là on a des modèles prédictifs (63 au total), dont un est expliqué dans le tutoriel: le Decision Tree. En plus on a aussi des modèles de segmentation (14), d’associations (6), de corrélations (8), de similarité (4) etc.
Parmi les autres modes de traitement de données, on a aussi la possibilité de créer des Macros qui sont un concept similaire aux variables dans la programmation et qui permettent d’effectuer des opérations complexes, comme décider combien de données visualiser et selon quel critère. Il est possible aussi de générer des tables en Excel ou autres formats et sauvegarder les bases de données traitées sur son ordinateur et beaucoup d’autres fonctionnalités encore.
Enfin RapidMiner permet de visualiser ces données à travers une vaste gamme de graphiques.
Visualisations offertes
En important une base de données, il est directement possible d’observer ces données sous forme de tableau simplement en cliquant sur “results” dans la barre principale et “data” dans la barre latérale. Si l’on prend par exemple, le tutoriel proposé par RapidMiner, il est possible d’obtenir plus d’informations concernant les passagers du Titanic.
En cliquant sur l'onglet “statistics” dans la barre latérale, on obtient des statistiques plus précises sur chaque colonne du tableau de l’onglet “data”. Par exemple, si l’on s’intéresse à l’âge des passagers, on peut voir que la moyenne d’âge est d’environ 30 ans, que la personne la plus jeune avait moins d’un an et que la plus âgée avait 80 ans.
En cliquant sur “open visualizations”, l’onglet “visualizations” dans la barre latérale s’ouvre. On peut choisir plusieurs types de visualisations. Les deux grandes catégories sont les graphiques (“charts”) et les cartes (“maps”). Dans la première, on retrouve 36 types de graphiques différents. Ils permettent de regarder les données de manière différente, en fonction de ce qu’on cherche à mettre en avant.
On peut par exemple utiliser le diagramme circulaire ou la pyramide pour montrer des pourcentages de différentes catégories de la base de données. Si l’on prend l’exemple du tutoriel, on pourrait par exemple voir le pourcentage de passagers ayant survécu ou non, tout comme le pourcentage de femmes ou d’hommes parmi les passagers. Egalement, on peut utiliser un diagramme en boîte. Avec celui-ci, on peut obtenir la valeur minimum et la valeur maximum d’une base de données, mais aussi la médiane et le 1er et 3ème quartile. Si l’on prend l’exemple du Titanic, on peut choisir le type de données à observer (âge par ex.) et si l’on souhaite diviser cette observation en différents groupes. Ainsi, on peut par exemple observer l’âge des passagers du Titanic en fonction de leur sexe:
On remarque alors que la femme la plus agée avait 76 ans, tandis que l’homme le plus âgé avait 80 ans. De plus, on peut voir que 50% des hommes avaient entre 30 et presque 1 an. Les autres 50% avaient entre 30 et 80 ans.
Pour ce qui est de la catégorie des cartes, on retrouve 3 types de cartes différentes. Les utiliser Pour l’exemple issu du tutoriel de RapidMiner, si l’on avait accès aux nationalités des passagers, on aurait notamment pu visualiser sur les cartes, le nombre de passagers par pays.
Points forts et limites
RapidMiner est certainement un outil qui offre une vaste gamme de possibilités et qui est flexible. Il possède une interface qui permet de visualiser le processus de traitement de données à travers un système de drag and drop où les opérateurs sont trascinés sur l’écran et mis en lien, cela donne ainsi au logiciel une interface intuitive et plaisante à utiliser. La quantité d’opérateurs à disposition permet aussi d’effectuer des traitements complexes sur les bases de données et d’extraire les informations qu'on nécessite de façon rapide et sans besoin de connaissances de programmation. Il y a également la possibilité de visualiser les données à travers nombreux modèles et graphiques rendant tout l’ensemble intéressant. Le fait d’avoir à disposition une version gratuite de RapidMiner pour l’éducation en permettant d’explorer toutes les fonctionnalités sans limitations, est aussi un point positif.
Cependant, malgré la présence d’un tutoriel qui nous aide à effectuer les premiers pas avec RapidMiner en nous familiarisant à certaines opérations de base, l’outil est très difficile à maîtriser, surtout pour ceux qui s’approchent pour la première fois du domaine de l’analyse et de l’extraction de données, aussi les instructions offertes par le site du logiciel ne sont pas toujour faciles à comprendre. Dans ce cas, la grande disponibilité d’opérations possibles se heurte à un temps d’apprentissage très long et une complexité qui peut effrayer les débutants et cela malgré la possibilité de visualiser les opérations. Un autre limite concerne l’accessibilité au niveau du prix. En effet, si l’on n’a pas droit à la version pour l’éducation qui est gratuite pendant un an et qui est quand-même limitée dans le nombre de données analysables, il faut acheter le produit pour profiter de tout son potentiel. Pour ce qui concerne le prix il y a aussi un manque de transparence, car cela n’est pas directement accessible sur le site web du producteur, mais en regardant les nombreux commentaires sur internet on nous laisse entendre que cela coûte cher. Pour terminer, RapidMiner est un outil qui n’est pas encore développé en français et même si on trouve rares documents en français sur internet, la langue peut être une barrière pour comprendre comment tout fonctionne.
Examples d'utilisation
Si les éditeurs de RapidMiner nous disent qu'il est possible de faire à peu près tout ce que l'on souhaite avec RapidMiner, une fois pris en main le logiciel n'est pas suffisamment intuitif et ergonomique pour trouver son chemin.
- J'ai donc choisi tout d'abord d'explorer une fonction de base du logiciel, c'est à dire le text mining.
- Dans un deuxième exemple, j'expliquerais comment utiliser concrètement les processus de text-mining pour miner et analyser des tweets sur Twitter.
Basic text mining
Comme décrit précédemment, nous allons tout d'abord voir de quelle façon RapidMiner mine du texte. Nous allons utiliser des processus de minage de texte servant à :
- Charger et extraire les mots de fichiers textes, de deux répertoires différents
- Ignorer certains mots non pertinents (stop list)
- Générer des résultats
- Visualiser ces résultats
La question à laquelle nous tenterons de répondre est : "Quels mots sont les plus représentés dans un corpus de textes relatifs au domaine de la littérature, et dans un corpus de textes du domaine de la photographie ?"
Lancement de RapidMiner et chargement des données


Lorsque vous lancez RapidMiner Studio (v. 6.1.1000) vous avez besoin d'installer l'extension de "Text Mining". En effet, RapidMiner travaille avec des extensions qui viennent se greffer au système central. Vous pouvez trouver l'extension de "Text Mining" sur le Marketplace (Aide > Mises à jour et Extensions (Marketplace))(fig. 1). Après avoir relancé le logiciel nous pouvons commencer à travailler. Créer un "Nouveau Processus", et vous devriez apercevoir l'affichage principal de RapidMiner Studio. Je vous présente ci-dessous les principales zones de l'espace de travail, que vous pouvez voir dans la Fig.2.
- La zone blue représente la barre d'outils principale.
- La zone orange nous montre les opérateurs que nous pouvons utiliser dans nos processus.
- La zone green nous montre nos répertoires (de données, locaux ou distants).
- La zone purple contient notre processus sous forme visuelle (les "blocs" processus et leur liens)
- La zone black contiendra les paramètres et l'aide du "bloc" processus selectionné
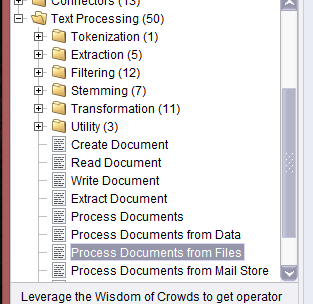
Pour commencer, nous pouvons utiliser un opérateur Process Documents from Files (screenshot ici) - processus de traitement de documents à partir de fichiers - que nous allons glisser dans notre zone du processus. Il faut ensuite régler les paramètres de notre processus, c'est à dire les répertoires distincts dans lesquels il va chercher les fichiers.

Note : Sur le coté droit de votre barre d'outils principale, vous pouvez voir quatre éléments qui vous permettent de basculer entre différentes étapes du processus global qu'est votre projet. Basculer entre le Design et les Results peut être très pratique lorsque vous n'avez pas les résultats attendus et que vous devez retourner modifier votre processus dans la page Design.
- Dans mon cas, j'avais un répertoire sur le bureau nommé "data"
- Dans /data/ il existe deux répertoires /litterature/ et /photographie/ dans lesquels se trouvent mes fichiers textes.
- Je n'ai qu'un fichier texte dans chaque répertoire mais je pourrais en avoir autant que voulu.
- Il faut donner un nom différent aux deux sources de fichiers pour pouvoir distinguer celles-ci dans les résultats
Dans la partie suivante nous allons parler d'opérateurs et nous allons revenir aux paramètres du processus Process Documents from Files pour choisir quel type de vecteur nous souhaitons créer.
Tokenize & définir les StopWords
Maintenant que nous avons notre processus Process Documents from Files (PDFF) au centre de notre espace de travail, et que celui-ci est relié en input et en output aux extrémités de cet espace, nous pouvons entrer dans ce processus et définir tous les sous-processus qui seront exécutés en son sein. Le input et le output se mettent en place en reliant à gauche inp (input) & wor (words) et à droite exa (exampleSet) & res (results). Ceci permettra aux données d'aller de la source à la destination.

Maintenant que nous sommes à l'intérieur de notre notre processus PDFF (en double cliquant dessus), nous pouvons définir deux opérations primordiales (Fig.5) :
- Tokenize : afin de couper les fichiers textes en input, et d'extraire leur contenu sous forme de mot à mot
- Filter StopWords : afin de ne garder que les mots "pertinents" (c'est à dire exclure les : LE; LA; LES; UN; ALORS, etc.). J'ai utilisé Filter StopWordsFrench puisque mes mots étaient en français.
Une des forces de RapidMiner est cette interface graphique qui, je dois l'avouer, devient quelque peut intuitive après les premières utilisations. Les input et les output ne sont pas rentrés en paramètre mais représentés sous la formes de lignes liant les différents opérateurs.
Voir les résultats
Si votre opérateur principal est connecté en entrée et sortie, et que dans lui-même, les opérateurs Tokenize et StopWords sont connectés comme le suggère la figure au dessus, vous devriez être prêts à lancer le processus générant vos résultats. Avant de cliquer bouton de lancement j'aimerais préciser que j'ai laissé le paramètre de type de vecteur par défaut. Ce paramètre vous permet de régler le type de vecteur devant être créé à l'issue du processus.
Si vous lancez le processus en laissant cette valeur (TF-IDF), RapidMiner vous présentera vos résultats de deux façons différentes : les onglets WordList et ExampleSet.
Note : Le TF-IDF "est une méthode de pondération souvent utilisée en recherche d'information et en particulier dans la fouille de textes. Cette mesure statistique permet d'évaluer l'importance d'un terme contenu dans un document, relativement à une collection ou un corpus". Wikipedia
Vue WordList

Dans la vue WordList (Fig. 6) nous avons notre analyse d'occurrences sous la forme d'un tableau.
- La première colonne nous montre tous les mots trouvés dans les documents (saufs StopWords)
- La seconde colonne nous les attributs de chaque mot (dans mon cas je n'en ai pas spécifié, c'est égal au mot lui même)
- La troisième colonne nous montre le nombre total d'occurrences (combien de fois le mot a été trouvé au total)
- La quatrième colonne nous montre le nombre total de documents dans lesquels on peut trouver le mot
- Les colonnes suivantes nous montre combien de fois le mot a été trouvé dans chaque répertoire
Ceci nous montre déjà les termes les plus occurrents, dans l'un et l'autre corpus, et permet déjà de vérifier si un mot commun à forte occurence dans les deux corpus existe.
Vue ExampleSet


Dans la vue ExampleSet (Fig. 7) nous avons un menu à gauche avec cinq onglets :
- Le premier onglet est une Vue d'ensemble du processus. Nous pouvons y trouver chaque répertoire ou corpus, chaque document traité et quelques autres informations.
- Le second nous montre des Statistiques relatives aux données traitées.
- Le troisième et quatrième onglet nous permettent de générer des charts ou graphiques afin de visualiser les résultats
- Le cinquième onglet permet à l'utiliseur d'ajouter des notes à son processus.
Note : La Fig.8 montre quelques possibilités de "charts" proposées par RapidMiner.
Exporter les résultats
Lorsque l'on souhaite exporter ses résultats directement depuis RapidMiner, chaque extension de RapidMiner dictera les possibilités de sorties. Dans notre cas, après avoir miné du texte, les données seront disponibles de façon différente selon la vue dans laquelle l'utilisateur se trouve. Oui l'exportation de données n'est au final qu'une capture de la vue selectionnée.
- La vue WordList nous permettra d'exporter le tableau en image (png, svg, jpg, eps, pdf), de l'imprimer ou même de copier son contenu dans un document Excel, Classeur ou Google Drive.
- La vue ExampleSet permet également de copier/coller des données depuis le logiciel, de l'importer et de l'exporter en tant qu'images aux formats ci-dessus
Miner des "Tweets" et les analyser
Introduction
RapidMiner Studio est capable à lui seul d'aller puiser dans Twitter et d'autres réseaux sociaux pour y puiser du contenu. Cependant cette fonctionnalité est non seulement reservée à la version payante du logiciel, mais elle nécessite en plus l'achats de crédits et l'activation des extensions Cloud, elles aussi payantes. J'ai donc choisi d'utiliser un service tiers pour l'extraction de tweets depuis Twitter.
Extraction des Tweets


Afin de construire notre corpus de texte, il nous faut obtenir sous n'importe quelle forme les tweets nous intéressant. Parmi tous les services tiers, beaucoup ne sont pas maintenus à jour ou n'existent plus et il est parfois difficile de trouver un service fonctionnant encore et qui sois gratuit. J'ai trouvé et décidé d'utiliser Zapier qui connecte les web-apps que vous utilisez afin de déplacer vos données ou créer des automatismes.
Pour notre tâche, j'ai connecté Twitter - en me connectant à mon compte Twitter personnel - à Google Drive - également en me connectant. J'ai ensuite spécifié un hashtag (#edtech) et demandé à Zapier de sauvegarder chacun des tweets contenant cette valeur dans un fichier texte individuel, dans un dossier sur mon compte Google Drive. Après quelques heures, des centaines de tweets avaient déjà été enregistrés, après quelquesjours c'était près de quatre mille tweets qui étaient là. Les screenshots proviennent d'une analyse sur quelques centaines de tweets.
Une fois que vous avez un nombre suffisant de tweets, vous pouvez télécharger votre dossier contenant tous vos tweets. Il faudra les placer quelque part sur votre ordinateur, afin de pouvoir les importer dans RapidMiner.
Transformation de données
Maintenant que l'on a notre corpus dans un répertoire, nous pouvons procéder et paramétrer ce répertoire en tant qu'input dans notre processus. J'ai créé trois processus différents, chacun d'eux composés des classiques Tokenize et FilterTokens pour ne garder que le contenu pertinent. La figure ci-dessous explicite ces processus.

Tout d'abord, concentrons nous sur le processus de couleur orange : Tweets processing
- Le bloc "Process Documents from Files" composé du Tokenize et StopWords comme vu précédemment
- Tokenize ne garde que les mots commençant par le symbole # (les hashtags)
- ... et un convertisseur qui converti des mots en données visualisables (en exampleSet).
Si l'on regarde le processus "URL Processing" :
- il fonctionne exactement de la même façon
- à l'exception qu'il ne garde que les liens, et donc les tokens commençant par http://
- ... et un convertisseur comme au dessus.
Finalement, le processus "Write excel process" est une solution alternative trouvée pour la visualisation des données. Mais j'y reviendrais un peu plus tard.
Analyse des données
Comme dit précédemment c'est une analyse quantitative sur les occurrences que nous exécutons là. Nous n'avons également constitué qu'un seul corpus.

Une fois le processus est correctement créé, vous pouvez l’exécuter et voir ci celui-ci vous donne les résultats attendus ou s'il y a eut un problème dans la conception. Si tout va bien, vous devriez avoir (si vous avez réalisé exactement les mêmes processus) trois ExampleSets, résultats des trois points de sortie - output.

Mon premier processus avait l'objectif de montrer quels hashtags étaient le plus représentés (sous forme de tableau et graphique)
Mon second processus a extrait les liens de tout le corpus de tweets et a classé ces liens selon le nombre d'occurrences. J'ai donc également cherché à savoir quels avaient été les liens les plus tweetés en compagnie de #edtecg.
Mon dernier processus, Write Excel, est la seule façon que j'ai trouvé dans RapidMiner pour filtrer des résultats. Un exemple, après avoir récupéré les hashtags les plus représentés j'aurais aimé pouvoir ignorer certains résultats (équivalents de #edtech et de #edchat p.ex.) ainsi que ne garder que les 100 hashtags les plus tweetés (afin de garder un graphique compréhensible) mais je n'ai trouvé aucune façon de le faire avec RapidMiner Studio. Ce processus importe dans RapidMiner un tableau excel, que j'ai créé à la main en supprimant les hashtags cités ci dessus. C'est grâce à ce processus que j'ai pu obtenir un graphique "visualisable". (Fig. 12)
Analyse de liens

{kind=link}
{kind=link}
Une fois les liens les plus tweetés obtenus j'ai cherché le moyen de ouvrir automatiquement une connexion à chacun des liens afin de récupérer le lien réel. En effet tous ces liens ont été raccourcis par le service de raccourcissement de URL de Twitter. Je voulais lancer ce processus afin de savoir quels étaient les sites (domaines) les plus souvent tweetés.
N'ayant pas trouvé d'outil ou de fonctionnalité dans RapidMiner pour cela j'ai choisi de simplement analyser de façon manuelle les cinq premiers liens. Non pas afin de tirer des conclusions sur les noms de domaines les plus présents, mais plutôt pour avoir une idée du type de contenu se trouvant derrière chacun de ces liens populaires.y.
Voici les cinq liens les plus populaires ainsi que la nature de la publication
- Photo humoristique à propos du fossé technologique générationnel (Twitter.com, 35 tweets)
- 9 traits d'un bon citoyen digital (Brilliant-Insane.com, 35 tweets)
- Infographie à propos de la citoyenneté digitale (Twitter.com, 35 tweets)
- Insightsed qui était indisponible - ressource limit is reached on 25.01.2015 @ 17:34 UTC+1 (29 tweets)
- 5 Strategies to Reach At-Risk Students with Technology (EdtechMagazine.com, 23 tweets)
Résultats et commentaires
Résultats de l'analyse des Tweets
- Tout d'abord nous avons vu que les lettres majuscules sont prises en compte dans les hashtags ce qui a créé une multitude de hashtags équivalents. Nous avons choisi #edtech mais avons obtenu des #EdTech, #Edtech or #edTech.
- Ensuite nous avons vu que le hashtag le plus représenté, de loin, était #edchat. On a observé que ces deux hashtags étaient souvent utilisés ensemble.
- Finalement, les autres hashtags les plus utilisés dans près de 700 tweets ont été : #education (132), #ipaded (117).
Résultats du traitement des URL
- Nous avons pu voir que les liens tweetés amènent au plus souvent à des articles de blogs dont le contenu principal est une image ou une infographie, ou à ces images elles-mêmes. Nous avons pu voir qu'outre des images et infographies, les liens pointent dans les autres cas vers des articles traitant à la fois le thème de l'éducation et de la technologie.
Commentaires
Cette analyse avait pour principal objectif de voir comment il était possible de réaliser une analyse d'occurrences avec RapidMiner. Bien sûr, je n'ai exploré qu'une petite partie des possibilités que le logiciel offre en terme de text-mining. Mes processus auraient cependant pu être améliorés :
- L'analyse de hashtags pourrait nous présenter quels hashtags ont été utilisés ensembles, combien de hashtags avaient été utilisés dans chaque tweet (et en moyenne). Cette analyse aurait également s'intéresser à la présence de marques et de plateformes (iOS) etc. pour y voir des tendances.
- L'analyse des liens aurait pu, comme dit précédemment, dévoiler le site réel derrière chacun de ces liens.
Finalement, il a été agréable d'utiliser RapidMiner bien que sa nouvelle formule payante rend frustrante l'utilisation de la version gratuite. De plus les fonctionnalités présentes ou pas ne sont pas explicitées, et l'aide respective à chaque processus n'est pas toujours présente (en anglais). Cependant RapidMiner a une approche très visuelle d'un processus de mining et après l'avoir utilisé pendant quelques heures, son utilisation devient aisée. Le plus compliqué étant toujours de fouiller parmi les modules disponibles et comprendre ce qu'ils permettent de faire ou pas.
Pour conclure, le logiciel profiterait beaucoup d'une refonte graphique ou de la modification de certains comportements tel la fonction de zoom arrière. En effet, pour dézoomer d'un graphique, il est nécessaire à l'utilisateur de cliquer avec le bouton gauche sur un endroit du graphique et de glisser la souris vers le haut-gauche. Aucune autre méthode classique ne permettait de réaliser cette opération. Une petite illustration des défauts ergonomiques que présente, à mon avis, parfois le logiciel.
Liens
Officiels
- Site officiel de RapidMiner. On y trouve des tutoriels vidéo.
- Le Wiki RapidMiner
- (utiliser la recherche ou "All pages" car la page d'accueil n'incluait à ce jour pas de liens de navigation.)
- Groupes de support pour RapidMiner (eng) -- Data Mining, ETL, OLAP, BI. Voir aussi cette entrée wiki
Obtenir RapidMiner
Documentation / Tutoriels (en anglais)
- Assignment 1: RapidMiner (Alex) (Text Mining, Brigham Young University)
- Stanford University Lane Medical Library article "What is RapidMiner?"
- Opinion Mining with RapidMiner - A Quick Experiment